AI's $700B Subsidy Clock Is Ticking
Token prices fell 280x but enterprise AI bills tripled. The hottest open-source project says use the LLM less.
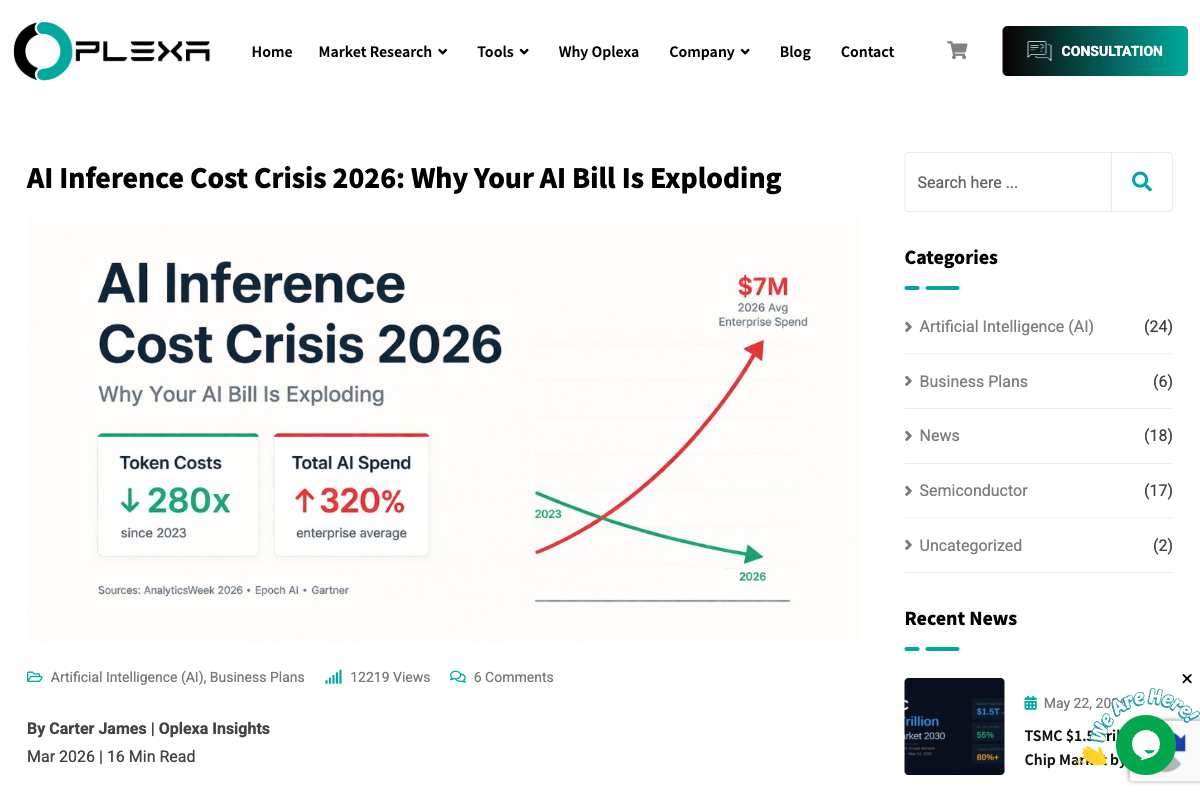
Here is a number that should make every AI team lead reconsider their 2026 budget: token prices have fallen 280x over two years. In the same window, total enterprise AI spending has risen 320%.
That is not a typo. It is the Jevons paradox made flesh — when a resource gets cheaper, people use so much more of it that total consumption explodes. And right now, the AI industry is living inside a version of that paradox so extreme that even the people building these systems are sounding the alarm.
"For my team, the cost of compute is far beyond the costs of the employees," Bryan Catanzaro, Nvidia's VP of applied deep learning, told Fortune. Read that again. The VP of deep learning at the company selling the shovels says the shovels cost more than the miners.
Meanwhile, the hottest open-source project on GitHub — gaining 2,503 stars in a single day — has a pitch that would have sounded absurd twelve months ago: use the LLM less.
Something has shifted. The vibe-spend era is ending. The dashboard era is beginning.
The Number That Broke the Model
The headline economics of AI look spectacular on a per-unit basis. A task that cost $30 per million tokens in early 2024 now costs roughly $0.10. GPT-4o input pricing halved. Newer models like o4 Mini offer input at $0.55 per million tokens. The price curve is a ski slope.
But zoom out from per-token pricing to total enterprise spend, and the picture inverts. The average enterprise AI budget has grown from $1.2 million per year in 2024 to $7 million in 2026. Inference now eats 85% of enterprise AI budgets, up from 40% in 2023. Some Fortune 500 companies report monthly AI inference bills in the tens of millions of dollars.
What happened? Three structural shifts hit at once.
First, agentic workflows. A year ago, a typical AI interaction consumed roughly 2,000 tokens. Today's agentic workflows consume 50,000 to 500,000 tokens per task. Gartner's March 2026 analysis puts the multiplier at 5–30x over a standard chatbot query.
Second, RAG inflation. Retrieval-augmented generation inflates context windows 3–5x per inference call, and those expanded contexts get re-sent with every turn of a multi-step agent loop.
Third, always-on agents. Unlike chatbots that activate on demand, monitoring agents and coding assistants consume compute 24/7. When Uber's CTO revealed that the company exhausted its entire 2026 AI coding budget in four months, it wasn't because tokens got expensive — it was because developers used them all the time.
headroom: The #1 Project Says 'Use the LLM Less'
Into this cost crisis walks headroom, a context compression layer built by a Netflix engineer named Tejas Chopra. Released June 4, 2026, it hit 14,600 stars in its first day and gained 2,503 stars in 24 hours — making it the fastest-growing project on all of GitHub by daily velocity.
The pitch is almost comically direct: compress everything your AI agent reads — tool outputs, logs, RAG chunks, files, conversation history — before it reaches the LLM. The claimed result: 60–95% fewer tokens, same answers.
headroom ships as a transparent proxy (zero code changes), a Python function (compress()), or a framework integration for LangChain, Agno, Strands, LiteLLM, and MCP. It includes six compression algorithms:
- SmartCrusher — universal JSON compression for arrays of dicts, nested objects
- CodeCompressor — AST-aware compression for Python, JS, Go, Rust, Java, C++
- Kompress-base — a HuggingFace model trained specifically on agentic traces
- CacheAligner — stabilizes prompt prefixes so Anthropic and OpenAI KV caches actually hit
- IntelligentContext — score-based context fitting with learned importance weights
- CCR — reversible compression where the LLM can retrieve originals on demand
The benchmarks claim accuracy is preserved: GSM8K math scores held at 0.870 with compression applied, and TruthfulQA actually improved slightly from 0.530 to 0.560. Real-world workloads show SRE incident debugging going from 65,694 tokens down to 5,118 (92% reduction) and code search from 17,765 to 1,408 (92%).
Early adopters report $700,000 in aggregate cost savings and 200 billion tokens freed since launch. Chopra's thesis: up to 90% of tokens sent to frontier models are redundant, primarily sourced from logs and database outputs.
The project's viral growth is not a coincidence. It is a market signal. When the most popular new tool in the entire open-source ecosystem is a token compressor, cost anxiety has gone mainstream.
If you want the hands-on setup guide, we covered headroom's architecture and integration paths in our AgentConn walkthrough. This article is the economics story. That one is the engineering playbook.
The Agentic Multiplier No One Budgeted For
Here is the math that breaks most AI budgets: a 10-turn agent session does not cost 10x a single call. It costs closer to 50x.
The reason is cumulative context re-sending. Each turn of an agentic loop sends the entire conversation history — every prior tool call, every response, every injected document — back through the model. By turn 10, you are paying for the same tokens nine times over.
And that's the visible cost. OpsLyft's analysis of enterprise AI deployments found that hidden costs — retrieval augmentation, embedding generation, context window management, retry logic — routinely add 40–60% on top of the raw inference bill that most teams track.
A Gartner analyst offered a warning that deserves to be bolted above every CTO's desk: "Chief Product Officers should not confuse the deflation of commodity tokens with the democratization of frontier reasoning."
Cheaper inputs do not mean cheaper outcomes. Especially not when the definition of "a task" has expanded from "answer this question" to "research, plan, execute, verify, and iterate across twelve tool calls."
The $700B Capex Question
Zoom out further — from enterprise budgets to the macro economy — and the same tension appears at infrastructure scale.
The five largest U.S. cloud and AI companies are guiding toward $635–690 billion in combined 2026 capital expenditure, more than double 2024 levels. Amazon alone is projected at $200 billion, a 50% jump from 2025. Q1 2026 AI capex totaled $174 billion, up 72.8% year-over-year.
ARK Invest projects AI infrastructure spending will reach $1.4 trillion by 2030. The trajectory looks like an exponential curve drawn by someone who hasn't slept in three days.
But here's the catch: capex growth is materially outpacing cloud revenue growth. Amazon's free cash flow is projected to turn negative in 2026. Morgan Stanley expects hyperscaler debt issuance to exceed $400 billion.
The Coastal Journal on Substack draws a striking parallel to the "dark fiber" era of 2000–2002: fiber capacity grew 100% annually while usage grew 50%, prices collapsed 40–60% per year, and Global Crossing went bankrupt. "Fiber eventually proved enormously valuable," the author writes, "but much of the return arrived 10–15 years later."

The question for AI infrastructure is the same: not whether the capacity will eventually be useful, but whether the companies building it today can service their capex commitments during what the Coastal Journal calls the "efficiency compression phase."
The 10x Paradox
On June 4, 2026, the All-In podcast hosted Thomas Laffont of Coatue for a 33-minute deep dive on what they called "The 10x Paradox" — why AI companies are achieving scaling at magnitudes previously unseen, and whether those multiples can last.
The episode sits at the intersection of this article's two threads. From the macro side: Coatue sees a $4 trillion AI IPO wave forming, with SpaceX at $1 trillion as the reference case. From the unit-economics side: consumption-based models are reshaping how Wall Street values AI companies, but only if the consumption actually maps to revenue that exceeds infrastructure cost.
The paradox is real. AI companies are growing 10x faster than historical cohorts. They are also spending 10x more on infrastructure than historical cohorts. The question is which 10x wins — the revenue multiplier or the cost multiplier. If headroom's GitHub velocity is any guide, the market is betting that cost discipline is the next phase.
Who Pays When the Subsidy Ends?
The dirty secret of 2024–2025 AI pricing is that much of it was venture-capital subsidized. OpenAI generated $3.7 billion in 2025 revenue while losing an estimated $5 billion — spending $1.35 for every dollar earned. Current API pricing reflects what VCs will tolerate, not what inference actually costs.
The Oplexa analysis recommends budgeting for "pricing normalization of 30–50% within 18 months." When — not if — the subsidies end, every enterprise AI deployment built on today's pricing gets repriced overnight.
We have already seen early tremors:
- Microsoft cancelled most Claude Code licenses six months after encouraging widespread adoption, citing unsustainable costs at scale.
- Uber exhausted its entire 2026 AI coding budget in four months despite starting with what seemed like a generous allocation.
- Google shifted from unlimited flat-rate AI pricing to metered AI Credits — a clear signal that all-you-can-eat is over.
- Notion disclosed a 10-percentage-point gross margin decline directly attributable to embedded AI costs.
The circular revenue problem makes it worse. Critics have noted that when Microsoft invests in OpenAI, OpenAI spends that money on Azure, and Microsoft books Azure consumption as fresh commercial revenue, the numbers flatter a system that is partially paying itself. OpenAI's annual cloud bill reportedly exceeds $60 billion while the company's actual revenue sits closer to $25 billion.
The Dashboard Era Begins
If the vibe-spend era was defined by teams adopting AI without asking what it costs, the dashboard era is defined by teams that cannot stop asking.
The emerging discipline is called "token governance" — monitoring and managing inference costs with the same institutional rigor that FinOps brought to cloud spend. The Artefact analysis argues that token governance may prove "as critical as capability development itself."
The practical toolkit is coming together:
- Model routing reduces inference spend by 60–80% by sending simple queries to cheap models and routing only complex tasks to frontier models
- Semantic caching cuts API calls by 30–50% for repeated or similar queries
- Context compression (headroom, rtk) eliminates redundant tokens before they reach the model
- On-premise inference delivers 70–90% cost reduction at scale for organizations willing to manage their own hardware
Goldman Sachs projects a 24-fold surge in token consumption by 2030. If that projection holds, cost optimization is not a nice-to-have — it is the difference between AI deployments that survive and ones that get cancelled when the CFO reviews Q3 numbers.
The companies that thrive in this phase won't be the ones with the most powerful models. They will be the ones with the best dashboards — the ones who know exactly which agent, which workflow, and which token is earning its keep.
What This Means For You
If you're building with AI in 2026, here is the minimum viable cost stack:
- Measure first. Instrument every LLM call with token counts and dollar costs. You cannot manage what you do not measure.
- Route aggressively. Not every task needs a frontier model. A well-tuned router can cut 60–80% of inference spend with no quality loss.
- Compress context. Tools like headroom and rtk exist specifically because context bloat is the #1 cost driver.
- Budget for repricing. Current API prices are subsidized. Build your cost models assuming a 30–50% price increase within 18 months.
- Watch the capex clock. If the dark compute thesis plays out and hyperscalers hit utilization stress, the downstream effects on API pricing and availability will be significant.
The subsidy clock is ticking. The question is not whether AI is worth the investment — it is. The question is whether your team has the cost discipline to survive the transition from subsidized to sustainable economics.
The vibe-spend era rewarded adoption. The dashboard era rewards efficiency. Start building the dashboard.
For the hands-on guide to headroom's architecture and setup, see the AgentConn operator walkthrough. For a deeper look at why per-token pricing is structurally misleading, read our analysis of the 6x pricing lie for reasoning models. And for context on how hardware costs feed back into this picture, see why memory is now two-thirds of AI chip costs.
ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
Join the discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related articles
GPT-5.6 Closed a 30-Year Math Gap. Nobody Noticed.
A prompt-guided GPT-5.6 attack proved an optimal lower bound in convex optimization while coverage of the same model decayed into pricing tips.
Open Models Now Run 63% of AI's Token Traffic
Mozilla's data shows open-weight models flipped from 5% to majority token share in two years. What the cost curve means for your inference stack.
The Open-Weight Frontier Arrived in a Single Day
Inkling and Kimi K3 shipped within 24 hours. Prediction markets repriced China, not Anthropic.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
WEEKLY. UNSUBSCRIBE ANYTIME.