Unlimited-OCR vs Mistral OCR 4: Which One Wins?
Baidu and Mistral both shipped OCR models the same day. One is open-weight and parses 40-page PDFs in one shot. The other costs $4/1K pages.
Two OCR models hit the Hacker News front page on the same day — June 22, 2026. Baidu's Unlimited-OCR pulled 447 points. Mistral's OCR 4 followed twelve hours later with 436 points. Combined: 883 points and 215 comments in a single news cycle, all about the same unsexy problem — getting text out of documents.
That doesn't happen by accident. Document parsing is the unglamorous backbone of every agent pipeline, every RAG system, every enterprise search stack. And for years, the available tools forced an ugly choice: pay per page for cloud APIs, or fight with open-source models that couldn't handle anything longer than a single page without chopping documents into slices and praying the reassembly worked.
Both of these models claim to end that era. But they do it from opposite directions — and the right choice for your pipeline depends entirely on which problem you're actually solving.
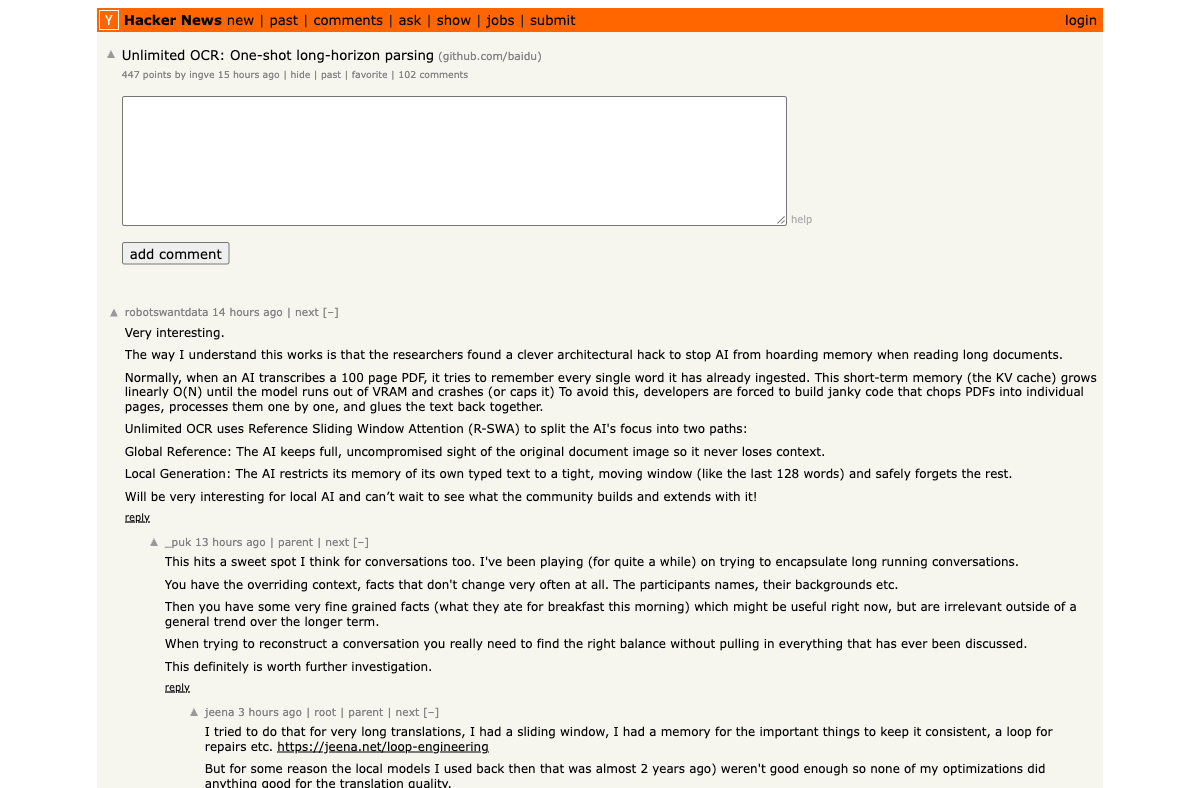
The Memory Problem That Unlimited-OCR Solves
Traditional OCR models built on decoder architectures hit a wall with long documents. As the model generates more output tokens, its KV cache grows linearly — consuming more memory and getting progressively slower with every page. The practical result: most teams manually slice PDFs into individual pages, process each one separately, and then reassemble the output with overlapping-window heuristics to catch text that spans page boundaries.
As one HN commenter described the workaround: developers routinely create "overlapping image slices with post-processing assembly" — a brittle pipeline that introduces errors at every seam.
Baidu's fix is architectural. Unlimited-OCR introduces Reference Sliding Window Attention (R-SWA), which replaces all attention layers in the decoder with a two-path mechanism:
- Global Reference: The model maintains complete visibility of the original document image — all visual tokens and prompt tokens stay in the attention window permanently
- Local Generation: The model's memory of its own generated text is limited to a sliding window of the most recent 128 tokens — older output tokens are evicted from the KV cache as new ones are generated
The result is a KV cache that stays constant regardless of document length. Where a traditional decoder's memory consumption scales as O(N) with output length, R-SWA keeps it at O(1). A 40-page document uses the same memory as a 4-page document.
The paper — authored by a team of 16 researchers at Baidu — positions R-SWA as a "general-purpose parsing attention mechanism" applicable beyond OCR to tasks like automatic speech recognition and translation. That's a bigger claim than just a better OCR model.
What You Get for Free
Unlimited-OCR is a 3B-parameter mixture-of-experts model with approximately 500M activated parameters per forward pass. It's built on DeepSeek-OCR's DeepEncoder architecture — a SAM-ViT cascaded with CLIP-ViT that compresses a 1024×1024 PDF page down to just 256 visual tokens. That 16× token compression, combined with the constant KV cache, is what makes single-pass multi-page processing practical on consumer hardware.
The model ships under an MIT license with support for vLLM, SGLang, Ollama, llama.cpp, and Hugging Face Transformers. It handles a 32,768-token context window, which translates to roughly 20–40 pages of dense text in a single inference pass.
On OmniDocBench v1.6, the standard benchmark for document AI in 2026, Unlimited-OCR scores 93.92 — placing it 5th overall behind PaddleOCR-VL-1.6 (96.33), MinerU2.5-Pro (95.69), GLM-OCR (94.62), and PaddleOCR-VL-1.5 (94.50). All five of those top models are open-weight and specialized — every single one beats frontier LLMs like Gemini 3 Pro (90.33) and Qwen3.5-397B (90.80) on raw document parsing.
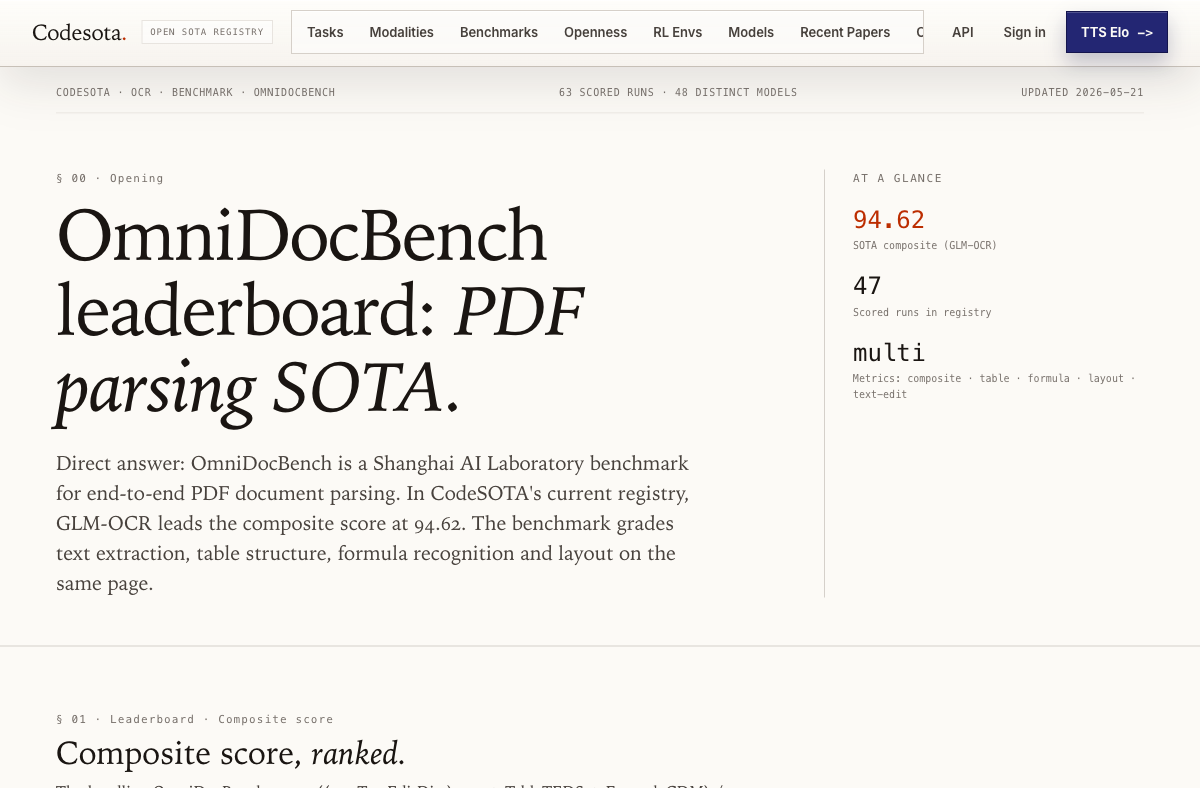
The HN community noticed. The top-rated comment called out Baidu's transparency as a "Class Act" for explicitly crediting DeepSeek-OCR and PaddleOCR in their acknowledgments — a rare gesture in an industry where corporate research labs typically minimize credit to external work.
Unlimited-OCR is MIT-licensed. You can run it locally, modify it, embed it in commercial products, and never pay per page. For teams already running local inference stacks, this is the most significant OCR release of 2026.
Mistral OCR 4: The Structured-Output Play
Where Unlimited-OCR solves a memory architecture problem, Mistral OCR 4 solves a structured-output problem. The model doesn't just extract text — it returns bounding boxes for precise element localization, typed block labels (titles, tables, equations, signatures), and per-word confidence scores.
That matters because most production document pipelines don't just need text. They need to know where each element sits on the page, what type of content it is, and how confident the model is about its extraction. Those three signals are what turn raw OCR output into something a downstream RAG pipeline or agentic workflow can actually use without human review.
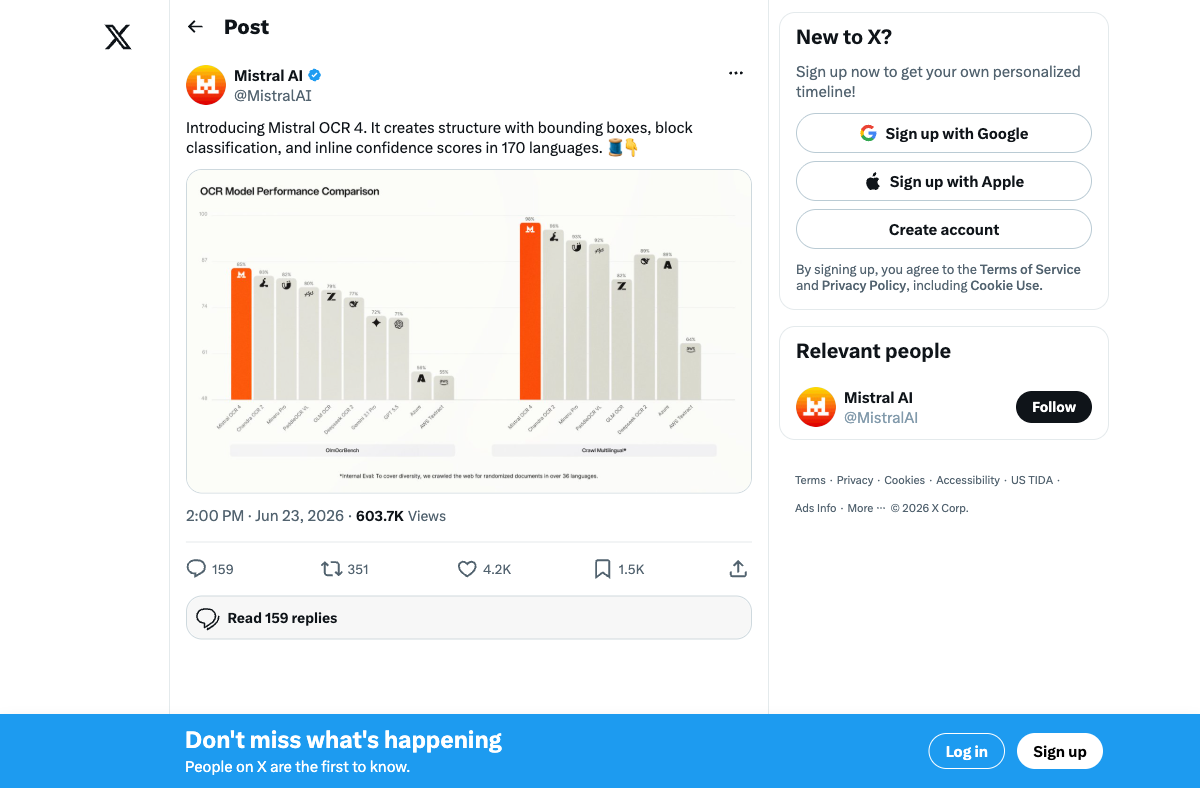
Mistral positions this explicitly for citation-ready structured output:
- RAG pipelines: Clean, classified blocks become superior retrieval units — you can chunk by semantic block type rather than arbitrary token windows
- Agentic workflows: Agents receive structural primitives (typed fields + bounding boxes) to act on documents programmatically — auto-filling invoice forms, extracting contract clauses, routing by document type
- Confidence-gated review: Per-word confidence scores let you build human-in-the-loop pipelines that only flag low-confidence extractions for manual review
The model handles 170 languages across 10 language groups, including low-resource languages where competing systems degrade. The HN discussion highlighted real-world validation: one commenter reported success "processing 55 year old paper files, most of them severely degraded" — scenarios where traditional OCR engines fail entirely.
Mistral OCR 4 integrates with the Mistral Search Toolkit, an open-source framework for building citation-ready search pipelines. If you're building enterprise document search, the structured output format slots directly into retrieval and evaluation workflows.
The Benchmark Picture
Benchmarks tell a split story. On OmniDocBench — the standard composite benchmark covering text extraction, table structure, formula recognition, and complex layout understanding — Unlimited-OCR leads decisively:
| Model | OmniDocBench Score | Type | Cost |
|---|---|---|---|
| PaddleOCR-VL-1.6 | 96.33 | Open-weight | Free |
| Unlimited-OCR | 93.92 | Open-weight (3B MoE) | Free |
| Mistral OCR 3 | 79.75 | Commercial API | $4/1K pages |
| Gemini 3 Pro | 90.33 | Commercial API | Variable |
But Mistral plays a different game. On OlmOCRBench — which evaluates extraction quality on a broader set of real-world documents — OCR 4 scores 85.20, the highest of any tested model. And in human evaluation with 600+ documents across 12+ languages, independent annotators preferred OCR 4's output over all competitors with a 72% average win rate.
The benchmarks aren't measuring the same thing. OmniDocBench tests raw parsing accuracy — how faithfully can you reproduce the original text? OlmOCRBench and human evaluation test usability — how useful is the extracted output for downstream tasks? Unlimited-OCR wins the first question. Mistral OCR 4 wins the second.
As one industry analysis noted: "Specialized models crush frontier LLMs on pure document parsing." Both Unlimited-OCR and Mistral OCR 4 are specialized — but specialized for different dimensions of the parsing problem.
Pricing: Free vs $4 Per Thousand Pages
The cost story is straightforward. Unlimited-OCR is MIT-licensed and runs locally — your only cost is GPU compute. On a single NVIDIA 4090, users in the HN thread reported successfully processing 200-page documents. At scale, hosting costs amortize to near-zero per page.
Mistral OCR 4 costs $4 per 1,000 pages through the standard API, or $2 per 1,000 pages via the Batch API (50% discount). The Document AI tier — which adds schema-based structured output — runs $5 per 1,000 pages. Deployment is available through Mistral Studio, Amazon SageMaker, and Microsoft Foundry, with a self-hosted single-container option for enterprise customers who need data sovereignty.
The HN discussion flagged the price increase: OCR 4 costs "double the price compared to their previous OCR v3 model from December." By comparison, Google Vision OCR costs $1.50 per 1,000 pages — though commenters clarified the services differ in scope, since Mistral's includes layout detection while Google's focuses on text extraction alone.
For enterprise customers processing millions of pages, Rogo reported equivalent accuracy at "8× lower cost and 17× lower latency" versus leading agentic parsers — suggesting that for teams currently using expensive multi-model pipelines, Mistral OCR 4 could reduce costs even at $4/1K pages.
If you're comparing costs, compare total pipeline cost — not per-page OCR cost. Unlimited-OCR is free but requires GPU infrastructure. Mistral OCR 4 costs per page but eliminates the post-processing pipeline you'd need to add structured output to Unlimited-OCR's raw text.
What Each Model Can't Do
Neither model is complete on its own. Here's where each falls short:
Unlimited-OCR limitations:
- No structured output — you get markdown text, not bounding boxes or confidence scores
- The 128-token sliding window means the model can't self-reference its own earlier output during generation (the tradeoff for constant KV cache)
- Tables and equations remain challenging — HN users acknowledged "struggles with tables and equations remain unsolved"
- No commercial API — you need GPU infrastructure and engineering effort to deploy
Mistral OCR 4 limitations:
- Commercial API with per-page pricing — costs scale linearly with volume
- Explicitly unsuitable for medical diagnosis, legal judgment, high-stakes financial decisions, and real-time processing
- Benchmark transparency concerns — HN commenters flagged that Mistral "reports flagship numbers from internal benchmarks" with charts using "truncated y-axes" starting at 50–95%
- Language categorization drew criticism — the initial "minor languages" terminology was updated to "specialized languages," but commenters noted this still marginalizes languages like Hindi and Japanese
Both models share a common limitation: hallucination risk. AI-based OCR can generate text that doesn't exist in the source document. For high-stakes extraction, neither eliminates the need for human verification.
The Decision Framework
Here's how to pick:
Choose Unlimited-OCR if:
- You're processing long documents (10+ pages) and need single-pass throughput
- You have GPU infrastructure and want zero marginal cost per page
- You need an MIT-licensed model you can modify and embed in commercial products
- Raw text extraction accuracy is your primary metric
- You're already running local AI inference stacks
Choose Mistral OCR 4 if:
- You need structured output (bounding boxes, block types, confidence scores) for RAG or agentic pipelines
- You're building citation-ready search systems that need element-level provenance
- You process documents in 170+ languages, including low-resource ones
- You want a managed API without GPU infrastructure overhead
- You need enterprise deployment options (SageMaker, Foundry, self-hosted container)
Consider both if:
- You have a pipeline where Unlimited-OCR handles high-volume bulk ingestion (free, fast, long-document capable) and Mistral OCR 4 handles the structured-output pass on the extracted content (confidence scoring, block classification, layout analysis)
The document-parsing frontier didn't just reopen — it forked. One track optimizes for throughput and openness. The other optimizes for structure and enterprise integration. The models that win in 2027 will probably merge both capabilities. But today, you get to pick which problem matters more for your pipeline.
What Happens Next
The OCR space is moving fast. PaddleOCR-VL-1.6 still leads OmniDocBench at 96.33 — both Unlimited-OCR and Mistral OCR 4 trail behind the pure parsing leaders. DeepSeek-OCR-2 (91.09) and GLM-OCR (94.62) are also in the mix. Mistral's broader position in European AI adds strategic context — OCR 4 is one of the few product lines where Mistral demonstrably leads American and Chinese competitors on specific metrics.
R-SWA is the technical development worth watching. If constant-KV-cache decoding works as well in practice as the paper claims, it's not just an OCR innovation — it's a fundamental architecture improvement applicable to any long-form generation task. The 16 Baidu researchers who built it clearly think so, positioning R-SWA as a "general-purpose parsing attention mechanism."
For teams building agent pipelines that need to read documents — and that's most agent pipelines — the choice just got a lot better. Whether you self-host Unlimited-OCR for bulk throughput or wire Mistral OCR 4 into your RAG stack for structured retrieval, the document-parsing bottleneck that's been holding back production agent systems just got substantially smaller.
About ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
💬 Join the Discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related Articles
Krea 2: Open-Weights Image Model That Caught the Frontier
Krea 2 is a 12B open-weights image model rivaling closed APIs. Here is what the technical report reveals and how to run it locally.
GLM-5.2 Is Cheap Because It's Subsidized, Not Efficient
GLM-5.2 burns 2x the tokens of its predecessor. The real cost edge is provider pricing — and it's repriceable overnight.
Z.ai Open-Sourced slime: GLM-5.2 Post-Training Stack
Z.ai released slime, the RL post-training framework behind GLM-5.2. Full OPD in 2 days. Here's why the factory matters more than the model.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
Weekly. Unsubscribe anytime.