DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7: Model Guide
DeepSeek V4 dropped today with 1M context at 1/6th the cost. Here's how it stacks up against GPT-5.5 and Claude Opus 4.7 for developers.

Today is the most chaotic single day in the 2026 AI model race.
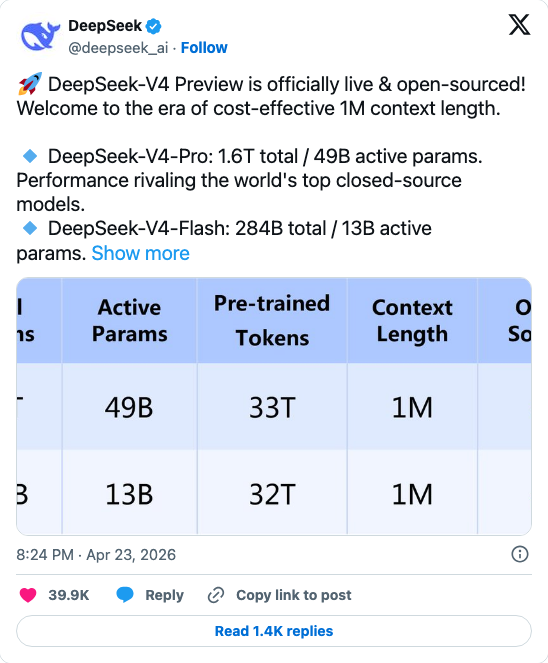
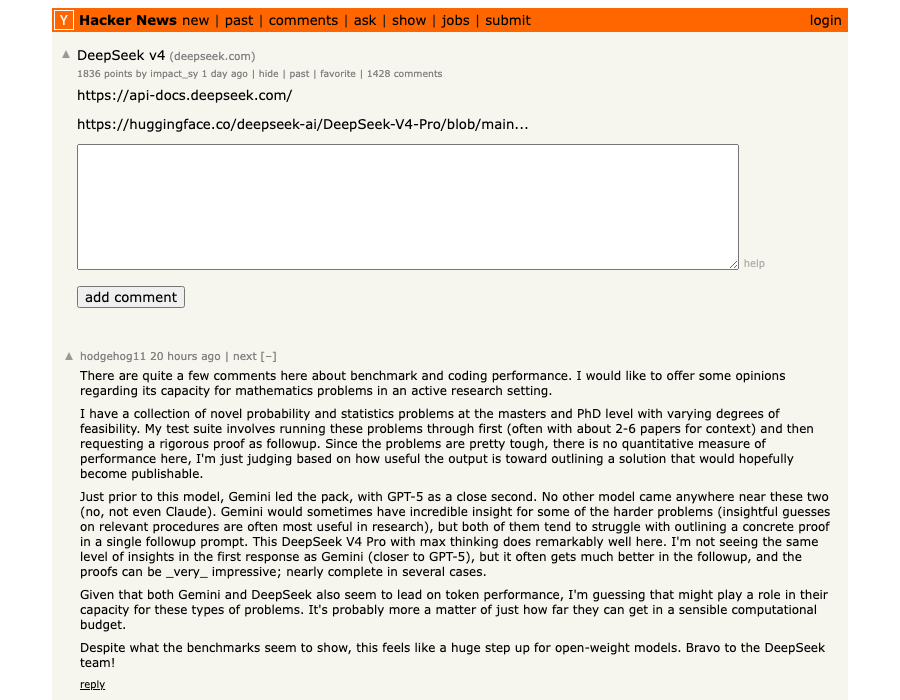
Within a 24-hour window, OpenAI shipped GPT-5.5 — its most capable API model yet, with a 74% long-context score that doubles its predecessor — and DeepSeek responded within hours with two open-source models: V4-Pro (1.6 trillion parameters, MIT license) and V4-Flash (284 billion, equally open). Claude Opus 4.7, which launched April 16, has been the dominant coding model since. Now it has two new challengers on the same day.
The timing is not a coincidence. It rarely is at this level.
For developers, this isn't an academic benchmark exercise. The question is practical: for your next sprint, which model do you route each task to? This guide gives you the data and the decision framework.
Read our GPT-5.5 vs Claude Code deep dive for the coding-specific head-to-head from yesterday's launch. This article covers the broader model selection question.
What Just Dropped: The Models at a Glance
Before comparing, here's what we're actually comparing:
| DeepSeek V4-Pro | DeepSeek V4-Flash | GPT-5.5 | Claude Opus 4.7 | |
|---|---|---|---|---|
| Total params | 1.6T | 284B | Undisclosed | Undisclosed |
| Active params | 49B | 13B | Undisclosed | Undisclosed |
| Context window | 1M tokens | 1M tokens | 1M tokens | 200K tokens |
| License | MIT (open weights) | MIT (open weights) | Proprietary | Proprietary |
| Input cost | $1.74/M | $0.14/M | $5.00/M | $5.00/M |
| Output cost | $3.48/M | $0.28/M | $30.00/M | $25.00/M |
| Self-hostable | Yes | Yes | No | No |
The architecture story behind these numbers: DeepSeek uses Mixture-of-Experts (MoE), which is why a 1.6 trillion parameter model only activates 49 billion parameters per token. Simon Willison notes that V4-Flash achieves only 10% of the single-token FLOPs and 7% of the KV cache size of its predecessor — that's what enables the aggressive pricing.
DeepSeek V4 runs entirely on Huawei chips with zero CUDA dependency. This matters beyond hardware specs: the inference pipeline isn't subject to US export control disruption, a meaningful consideration for enterprise planning.
Benchmark Breakdown: Who Wins Where
Raw benchmark numbers are imperfect, but they're what we have. Here's the honest picture:
Intelligence Index (Artificial Analysis)
- GPT-5.5: 60 points (top score)
- Claude Opus 4.7: 57 points
- DeepSeek V4-Pro: competitive, positioned between the two above
GPT-5.5 leads the overall intelligence index — but three points over Claude Opus 4.7 is a margin unlikely to be decisive in most production workloads.
Coding (SWE-Bench Verified)
- Claude Opus 4.7: 87.6% (+6.8 points over Opus 4.6)
- DeepSeek V4-Pro: 80.6%
- GPT-5.5 Pro: 58.6% (notably behind)
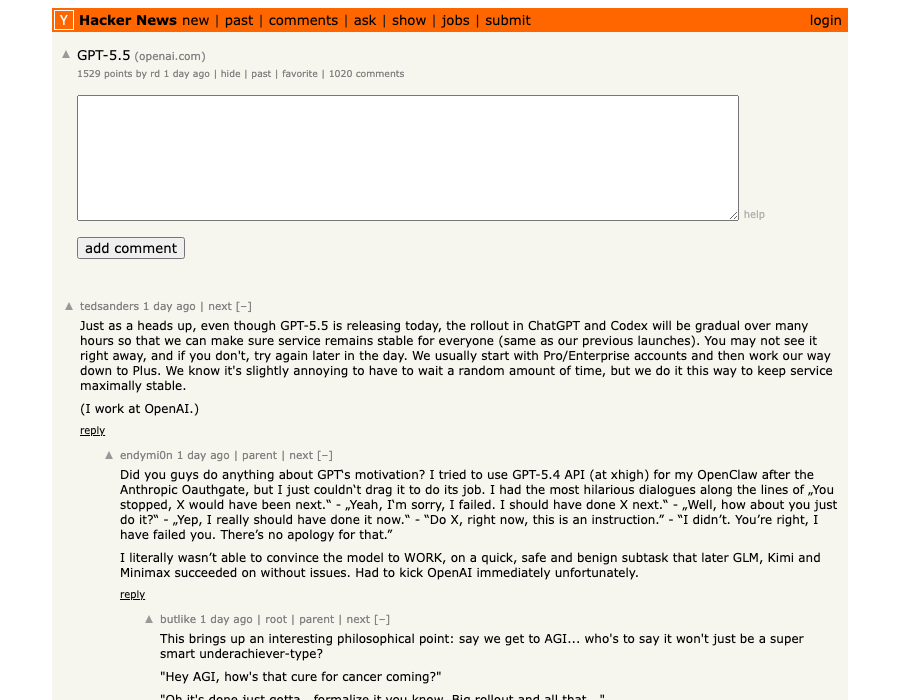
For pure coding tasks, Claude Opus 4.7 holds the highest verified score at 87.6% on SWE-bench. DeepSeek V4-Pro is competitive at 80.6%. GPT-5.5 Pro trails at 58.6% — a surprising gap given its overall intelligence lead.
DeepSeek also leads on terminal-level coding: V4-Pro scores 67.9% on Terminal-Bench 2.0 vs Claude at 65.4%. These are close enough that real-world workload matters more than the benchmark gap.
Hard Reasoning (Humanity's Last Exam, no tools)
- Claude Opus 4.7: 46.9%
- GPT-5.5 Pro: 43.1%
- GPT-5.5: 41.4%
- DeepSeek V4-Pro: 37.7%
This is the most revealing split. For tasks requiring genuine hard reasoning — the kind where neither model has a template to pattern-match from — Claude Opus 4.7 leads by 9 points over DeepSeek. That's a meaningful gap for legal, financial analysis, or complex research workloads. (FundaAI 38-task benchmark)
GPT-5.5's documented 86% hallucination rate — per The Decoder's independent testing — is a significant weakness despite its top intelligence index score. For factual grounding, Claude Opus 4.7 or DeepSeek V4-Pro are more reliable.
Long-Context Reasoning (MRCR v2 at 1M tokens)
- GPT-5.5: 74.0% (up from 36.6% in GPT-5.4 — an extraordinary jump)
- Claude Opus 4.7: strong, but only supports 200K native context
- DeepSeek V4-Pro: 1M context native, performance data pending
The GPT-5.5 long-context improvement is the headline technical achievement of this launch. If your workload involves very long document processing, GPT-5.5's long-context reasoning may be worth the price premium.
The Real Cost Math
This is where DeepSeek V4 becomes genuinely disruptive. Let's make the numbers concrete for a typical development team.
Assume 100M output tokens per month (a moderately active team with LLM-intensive workflows):
| Model | Monthly Output Cost |
|---|---|
| GPT-5.5 Pro | $18,000 |
| GPT-5.5 | $3,000 |
| Claude Opus 4.7 | $2,500 |
| DeepSeek V4-Pro | $348 |
| DeepSeek V4-Flash | $28 |
DeepSeek V4-Pro at $348 vs Claude Opus 4.7 at $2,500 is a 7× cost difference for near-comparable coding performance. V4-Pro's output cost versus GPT-5.5 Pro is a 98% reduction.
For teams already running on a budget, we covered a similar cost calculus in our Kimi K2.6 vs Claude Opus 4.7 comparison — the pattern of Chinese open-source models delivering 80–90% of the capability at a fraction of the cost is now a structural feature of the AI market, not an anomaly.
With cached input, the gap widens further. DeepSeek-V4-Pro's cache-hit cost is roughly one-tenth of GPT-5.5 and one-eighth of Claude Opus 4.7 at scale. If your architecture reuses prompt prefixes, the savings compound aggressively.
The 1M Context Window: What It Actually Changes
Both DeepSeek V4 models and GPT-5.5 ship with 1M token context windows. Claude Opus 4.7 caps at 200K. The practical implications:
What 1M tokens enables:
- Feeding an entire 500-page technical specification into a single prompt
- Six months of project documentation without chunking
- A full codebase (~750,000 words of active context)
- Multi-step agent workflows where the model retains chain-of-thought across 20+ tool calls
DeepSeek V4 introduces "interleaved thinking" — full chain-of-thought retention across tool calls in agent workflows. This means a 20-step agent workflow doesn't suffer the amnesia-halfway-through problem that plagues most agentic pipelines.
The HN discussion at 1,588 points surfaced a key practical detail: DeepSeek's zero CUDA dependency makes it runnable in environments where Nvidia GPUs aren't available — relevant for enterprise deployments on private infrastructure.
The Polymarket Divergence: Hype vs. Market Confidence
Here's the contrarian data point most coverage will skip.
The Polymarket market "DeepSeek V4 released by...?" had $2.4 million in trading volume and resolved at 100% — traders called the release date correctly. Developer enthusiasm is genuine.
But Polymarket's "Best Chinese AI company 2026" market? DeepSeek sits at 3%.
That divergence — maximum developer excitement, minimal market confidence in DeepSeek as a company — is worth sitting with. Some reasons the market might be right:
- Open-source models generate developer mindshare but not revenue
- DeepSeek's pricing is so aggressive it may be below sustainable margin
- US export restrictions on Nvidia GPUs create a hardware ceiling for scale
- Anthropic holds ~85% in the "best coding AI company" Polymarket market — consensus hasn't shifted despite DeepSeek's coding scores
The pattern is clear: open-source is the Chinese AI strategy for global developer mindshare while keeping closed models for domestic enterprise. Two major drops (DeepSeek V4 + Tencent Hy3 at 295B parameters) in one day is not a coincidence. (Tencent Hy3 launch)
Decision Framework: Routing Logic by Task Type
The FundaAI 38-task benchmark and the Artificial Analysis comparison both land at the same conclusion: don't pick one model. Route.
Route to Claude Opus 4.7 when:
- Hard reasoning is required (legal, financial, medical research)
- Code review or complex multi-file refactoring (87.6% SWE-bench)
- Citation accuracy matters — lowest hallucination rate
- Enterprise compliance rules out Chinese infrastructure
- You're already in Cursor (50% off right now)
Route to DeepSeek V4-Pro when:
- Long-context analysis (1M token codebase ingestion, multi-document synthesis)
- Agentic workflows with 20+ steps (interleaved thinking retention)
- High-volume batch processing where cost is the constraint
- Self-hosting or private infrastructure is required
- You want open weights for fine-tuning on domain data
Route to DeepSeek V4-Flash when:
- High-frequency, lower-complexity tasks ($0.28/M output)
- First-pass triage or pre-processing before escalation to a stronger model
- Any use case where V4-Pro would work but volume makes cost prohibitive
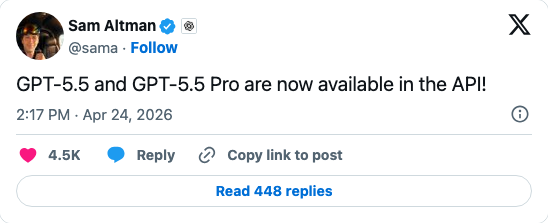
Route to GPT-5.5 when:
- Extreme long-context reasoning (1M tokens, MRCR v2 at 74%)
- Agentic computer use tasks via OpenAI Codex
- Speed is a priority (GPT-5.5 Fast Mode: 1.5× faster tokens)
- Deep OpenAI ecosystem integration (ChatGPT, Codex)
Skip GPT-5.5 Pro unless:
- You have specific enterprise contracts with OpenAI
- The $180/M output cost is justifiable for specialized, low-volume, high-stakes tasks
- The 58.6% SWE-bench score won't matter for your use case
The optimal architecture for most teams: route 60–70% of traffic to V4-Flash for high-volume/low-complexity tasks, escalate coding to Claude Opus 4.7, use GPT-5.5 for long-context document tasks. This pattern typically reduces costs 40–60% compared to running everything through a single frontier model.
The Bottom Line
Three models, three different bets on what matters:
Claude Opus 4.7 is the best coding model at 87.6% SWE-bench verified. It leads on hard reasoning. It hallucinates least. It costs $25/M output tokens. For high-stakes code and reasoning work, it remains the default.
DeepSeek V4-Pro is 7× cheaper than Claude, open-source, and within 10 points on most coding benchmarks. The 9-point gap on Humanity's Last Exam matters for hard reasoning. For everything else, the cost case is compelling — especially with 1M context native and interleaved thinking for agents.
GPT-5.5 wins the intelligence index at 60 points and made a massive long-context leap. But the 86% hallucination rate and $30/M output cost make it a niche choice: buy it when you specifically need that long-context reasoning, and verify outputs carefully.
The frontier in 2026 is not a single model. It's a routing layer.
For the coding-specific comparison, see GPT-5.5 vs Claude Code: Which AI Should You Use for Agentic Development?
For a deeper look at the Chinese open-source cost story, see Kimi K2.6 vs Claude Opus 4.7: The 88% Cost Advantage
ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
Join the discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related articles
Cursor Router Claims 60% Savings. It Also Sees Every Prompt.
Vendor model routing is a cost AND data control point. Why open-source routers are the contested infrastructure play.
Speech AI Fits in 500KB. The Cloud Bill Was Never the Point.
Moonshine and transcribe.cpp shrink speech AI to sub-megabyte, but the real shift is architectural guarantees over policy promises.
GPT-5.6 Looks Cheaper. Your Invoice Won't Agree.
Sol's $5/1M token sticker hides reasoning burn. Cost-per-task data shows who really pays more.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
WEEKLY. UNSUBSCRIBE ANYTIME.