The AI Memory Squeeze Has Hit Your Wallet
Apple just hiked MacBook and iPad prices. DRAM is up 90%. Here's what the AI-driven memory crunch means for your next local-inference build.

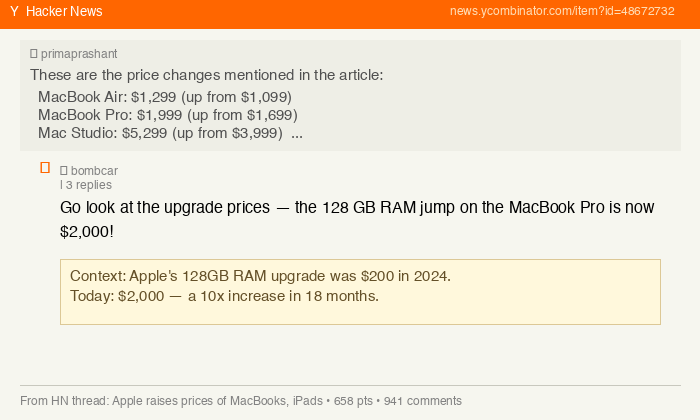
Apple raised prices on MacBooks, iPads, HomePods, Apple TV, and Vision Pro today — June 25, 2026. The increases are not small. A MacBook Pro with 1 TB of storage jumped from $1,699 to $1,999. An iPad Air with 128 GB of storage went from $599 to $749. A top-spec Mac Studio climbed by $1,300. Tim Cook, who spent decades at Apple building the most disciplined supply chain in consumer electronics, called the memory shortage a "hundred-year flood" and told The Wall Street Journal that the situation has "become unsustainable."
The news coverage will focus on the sticker shock. This piece is about the transmission mechanism underneath it — and what it means if you are building or planning a local-AI inference rig in 2026.

The 70/30 Split That Explains Everything
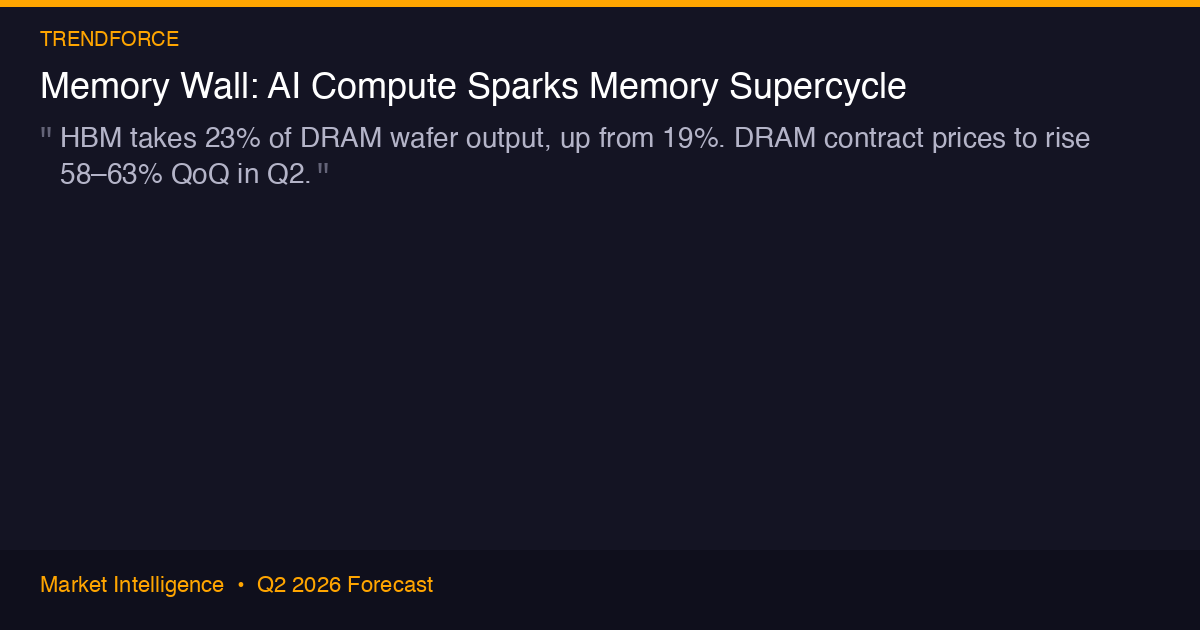
The root cause is a single number: data centers now consume roughly 70 percent of all memory chips produced globally, according to TrendForce. That leaves 30 percent for every smartphone, laptop, tablet, game console, and desktop PC on the planet.
This is not a demand blip. It is a structural reallocation. Samsung, SK Hynix, and Micron — the three companies that control over 95 percent of global DRAM production — have systematically shifted manufacturing capacity toward high-bandwidth memory (HBM) chips used in AI accelerators. HBM now takes up 23 percent of total DRAM wafer output, up from 19 percent last year. HBM capacity for 2026 is entirely sold out. Manufacturers are refusing new orders.
In December 2025, Micron announced it would exit the consumer memory and storage market entirely to focus on AI data center customers. One of the Big Three just walked away from you and me as customers. That is the clearest signal of where the industry's priorities lie.
The result: conventional DRAM contract prices jumped around 90 percent in early 2026, according to IEEE Spectrum. TrendForce projects another 58 to 63 percent increase in Q2. NAND flash is rising 70 to 75 percent alongside it. These are not consumer prices — they are the contract prices that manufacturers like Apple pay. When those contracts reprice, retail follows. Today was that day.
The transmission chain. AI capex → hyperscaler DRAM demand → fab capacity reallocation → HBM priority → conventional DRAM undersupply → contract price spike → Apple/Microsoft/everyone raises consumer prices. Your MacBook got more expensive because OpenAI needed more memory.
What Apple's Price Hike Actually Tells You
Apple's price increases are the most visible symptom because Apple is the most visible company. But Microsoft raised Surface prices the same week. Dell, HP, and Lenovo have been quietly raising enterprise laptop prices since Q1.
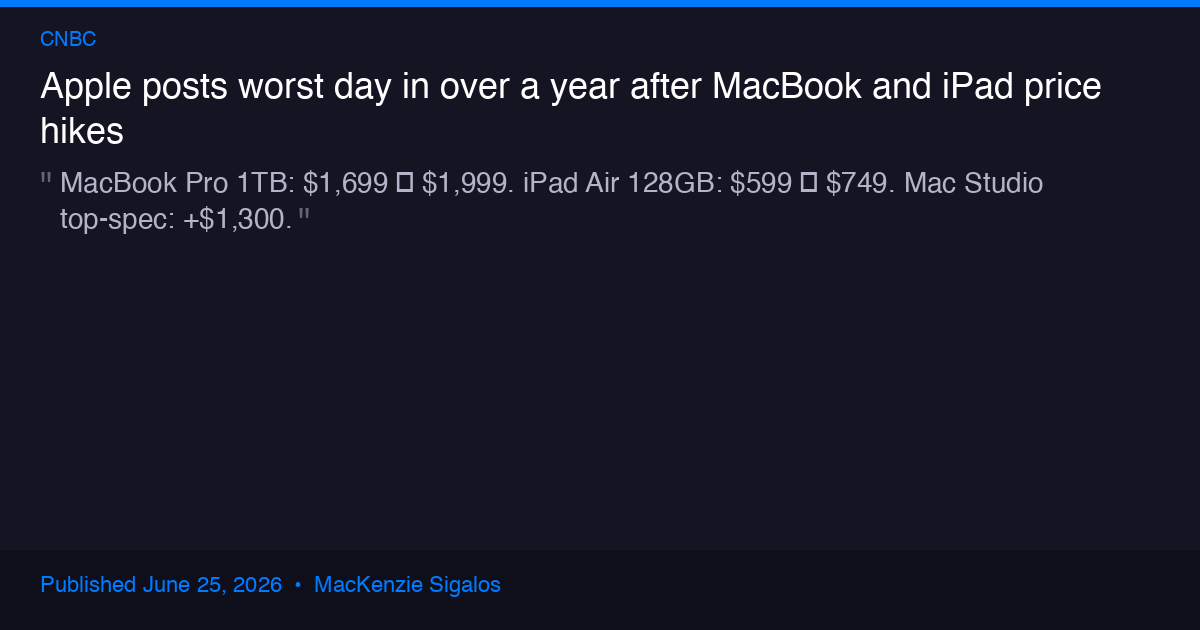
The Apple-specific numbers matter because they reveal the magnitude. Tim Cook told investors that the DRAM in an iPhone 17 Pro cost Apple about $39. The same memory for the iPhone 18 Pro is projected to cost $145 — a 272 percent increase. That is why analysts expect the iPhone to see its own price hike at the fall launch.
Apple spared the iPhone, Apple Watch, and AirPods in this round. But CNBC reports that analysts widely expect the iPhone to be hit at the September launch, since it relies on the same DRAM supply chain. The only question is how much Apple can absorb before passing the rest through.
For ComputeLeap readers, the takeaway is not "Apple products cost more." It is this: if Apple, with the largest component purchasing power on Earth, cannot shield its prices from the memory squeeze, no one can. Every device that needs DRAM or NAND — including every GPU, every workstation, every NAS — is downstream of the same price pressure.
The Local-AI Builder's Problem
This is where the story gets personal for anyone running models locally. We wrote in May about how memory now accounts for two-thirds of AI chip costs — the supply-side story of HBM eating the silicon bill of materials. Today's price hikes are the consumer-side echo of that same structural shift. And if you are building a local-inference rig, you are sitting in both supply chains at once.
RAM: The Quiet 3x
A 32 GB DDR5-6000 kit that cost around $80 in mid-2025 now starts at $190–$220, according to Tom's Hardware's price tracking. That is roughly a 2.5–3x increase. DDR5 averages $14.12 per gigabyte in 2026, up from around $3/GB at mid-2025 lows. DDR4, for those on older platforms, is cheaper at $9.08/GB but still up 30–60 percent year-over-year.
For running a 70B-parameter model locally, you need 64–128 GB of system RAM in a CPU-inference setup. That kit — which cost $160–$320 eighteen months ago — now runs $450–$900. The memory alone has added $300–$600 to a build that used to be within hobbyist reach.
GPUs: The VRAM Tax
The GPU side is worse. NVIDIA's RTX 5090, which launched at $1,999, now commands $3,000–$4,000 at retail, with industry sources predicting $5,000 by late 2026. Secondary market prices have hit $6,000 — a 190 percent markup.
The reason is the same: GDDR7 memory has seen a 40 percent price increase by Q2 2026, and VRAM now accounts for more than 80 percent of the total bill of materials for some high-end GPUs. NVIDIA has reportedly cut GeForce RTX production by 30 to 40 percent to manage the constraint. You are paying more for a card that is harder to find because the memory inside it is being rationed.

Storage: The Quiet Third Squeeze
NAND flash is rising 70–75 percent alongside DRAM. If you are building a rig with fast NVMe storage for model weights and KV caches, budget accordingly. A 4 TB NVMe that was $200 last year is now $350+.
The Buy-vs-Wait Calculation
Here is the practical question ComputeLeap readers are asking: should I build now, or wait for prices to come down?
The honest answer depends on your timeline.
The bear case for waiting: Investing.com analysis calls this shift "structural, not cyclical," with supply expected to remain constrained through 2027. New fabrication capacity is coming online in late 2026 and early 2027, but analysts do not expect a return to the rock-bottom pricing of 2023–2024. The new baseline will be higher.
The bull case for building now: DDR5 prices are actually down about 20 percent from their March 2026 peak. If you are reading this in late June, you may be in a local trough before the next quarterly contract repricing pushes costs up again. The 58–63 percent QoQ increase TrendForce projects for Q2 has not fully flowed through to retail yet.
The component-by-component verdict:
- DDR5 RAM (32–128 GB): Buy now if you need it. Prices are off their March peak, and the next contract cycle will push them higher. DDR4 is a viable alternative if your platform supports it — 30–60% cheaper per GB.
- GPU (RTX 4090/5090): Wait if you can. GPU prices are still climbing, and the RTX 5090 supply situation may improve modestly in Q4 as NVIDIA ramps GDDR7 procurement. Used RTX 4090s are a better value-per-VRAM-dollar right now.
- NVMe storage: Buy now. NAND prices are rising but not as sharply as DRAM. Current NVMe deals are better than what Q3 will offer.
- CPU (for CPU-only inference): Prices are stable. CPU silicon is not memory-constrained. Buy when ready.
What the Smart Builders Are Doing
The community response has been to rethink architectures, not abandon them. In the Hacker News discussion on today's Apple price hikes, several of the top comments come from local-AI builders adapting to the new reality rather than retreating to cloud-only inference:
- Quantization is king. Running a 70B model in 4-bit quantization (GGUF Q4_K_M) cuts RAM requirements from ~140 GB to ~40 GB — the difference between a $900 memory kit and a $280 one. The quality trade-off, which was steep two years ago, has narrowed significantly with better quantization methods. For most personal-use cases — code completion, document Q&A, summarization — a well-quantized 70B model is indistinguishable from the full-precision version.
- Used GPUs over new. RTX 4090s on the secondary market offer 24 GB VRAM at $1,200–$1,500 — roughly the same price-per-VRAM-GB as a new RTX 5090 at $4,000 for 32 GB, but available now. The 4090's GDDR6X is not subject to the same GDDR7 shortage. Multiple HN commenters report buying two used 4090s for multi-GPU inference at the price of a single new 5090, getting 48 GB total VRAM.
- CPU inference is back. With DDR5 prices still lower per GB than GDDR7, some builders are pivoting to CPU-only inference with high-RAM configurations. A 128 GB DDR5 build running llama.cpp can serve a quantized 70B model at acceptable speeds for personal use — and the total build cost is lower than a single RTX 5090. The trade-off is speed: GPU inference is 5–10x faster for batch generation, but for interactive chat with a single user, CPU inference at 10–15 tokens per second is perfectly usable.
- Apple Silicon as the middle path. The irony is that Apple's own M4 Pro and M4 Max chips — with unified memory that serves as both RAM and VRAM — remain one of the most cost-effective platforms for local inference per dollar of memory, even after today's price hikes. A Mac Mini with 64 GB unified memory costs more than it did last month, but it still undercuts a discrete-GPU rig with equivalent VRAM capacity. We explored this in depth in our piece on the iPhone 17 Pro's on-device AI capabilities.
We covered the practical side of building inference rigs in our guides to running AI locally with DGX Spark and Unsloth and setting up local AI as your default. The hardware advice in those pieces still holds, but add 50–100 percent to the memory line items if you are pricing a build today.
The Structural View
Zoom out one more level. This is not a one-quarter event. Samsung has warned that memory shortages will drive industry-wide price surges through 2026. SK Hynix has said its DRAM and NAND capacity is "essentially sold out" for the year. The AI capex buildout that is driving this demand shows no sign of slowing — if anything, it is accelerating as every major tech company races to deploy frontier models.
The supply side will eventually catch up. New DRAM fabs take 18–24 months to bring online. Samsung and SK Hynix have both announced capacity expansions planned for late 2026 and into 2027. But "catching up" does not mean "returning to 2024 prices." The memory market is repricing permanently higher, because AI demand is not temporary — it is the new floor.

There is a deeper dynamic worth understanding here. The HBM4 generation, which Samsung and SK Hynix are accelerating into production to meet NVIDIA's Rubin architecture demand, requires even more wafer area per chip than HBM3e. Each generation of HBM that serves the AI datacenter takes a larger bite out of the shared wafer pool that consumer DRAM comes from. The squeeze does not ease as AI scales — it deepens.
Meanwhile, the demand floor is being set by long-term agreements. In late 2025, Samsung and SK Hynix signed a letter of intent with OpenAI to supply 900,000 DRAM wafers per month for the Stargate project alone. That is a multi-year commitment that locks wafer capacity away from the consumer market regardless of what spot prices do. Even if DRAM demand from the broader tech industry softened tomorrow — and it will not — these locked-in contracts would keep supply tight.
The Bottom Line
For local-AI builders, the implication is clear: the golden age of cheap local inference hardware is over. The $800 inference rig we wrote about in early 2025 is a $1,500 rig now, and it may be a $2,000 rig by year-end. That does not mean local AI is dead — it means the economics have shifted, and the smart move is to optimize for the new reality rather than wait for the old one to come back.
The playbook is straightforward: buy DDR5 and NVMe now while they are off their March peaks, hold on GPUs if you can afford to wait for Q4 supply improvements, lean hard into quantization to reduce your memory footprint, and consider the used RTX 4090 market before paying the GDDR7 tax on a new 5090. If you are on Apple Silicon, the unified-memory architecture just became a more compelling value proposition, even at today's higher prices.
The memory squeeze is real, it is structural, and as of today, it is in your wallet. Plan accordingly.
About ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
💬 Join the Discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related Articles
Apple Paying Google $1B/Year to Run Siri on Gemini
Apple outsourced Siri's brain to Google Gemini in a $1B/year deal. Here's the architecture, the antitrust risk, and what it means.
Why the US Government Pulled Fable 5
Amazon's jailbreak demo triggered an export-control order that killed Anthropic's best model in 72 hours — and set a precedent every frontier lab now fears.
Is the AI Scaling Law Breaking? The Capex Math
The financing window opens the same week researchers ask when scaling stops paying off. Inside the $720B capex-vs-capability tension.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
Weekly. Unsubscribe anytime.