Is the AI Scaling Law Breaking? The Capex Math
The financing window opens the same week researchers ask when scaling stops paying off. Inside the $720B capex-vs-capability tension.
The same week SpaceX listed on Nasdaq and Elon Musk became the world's first trillionaire, a quieter conversation was gaining speed across research labs, investor newsletters, and Hacker News threads: what if the money stops working?
Not the models. The money.
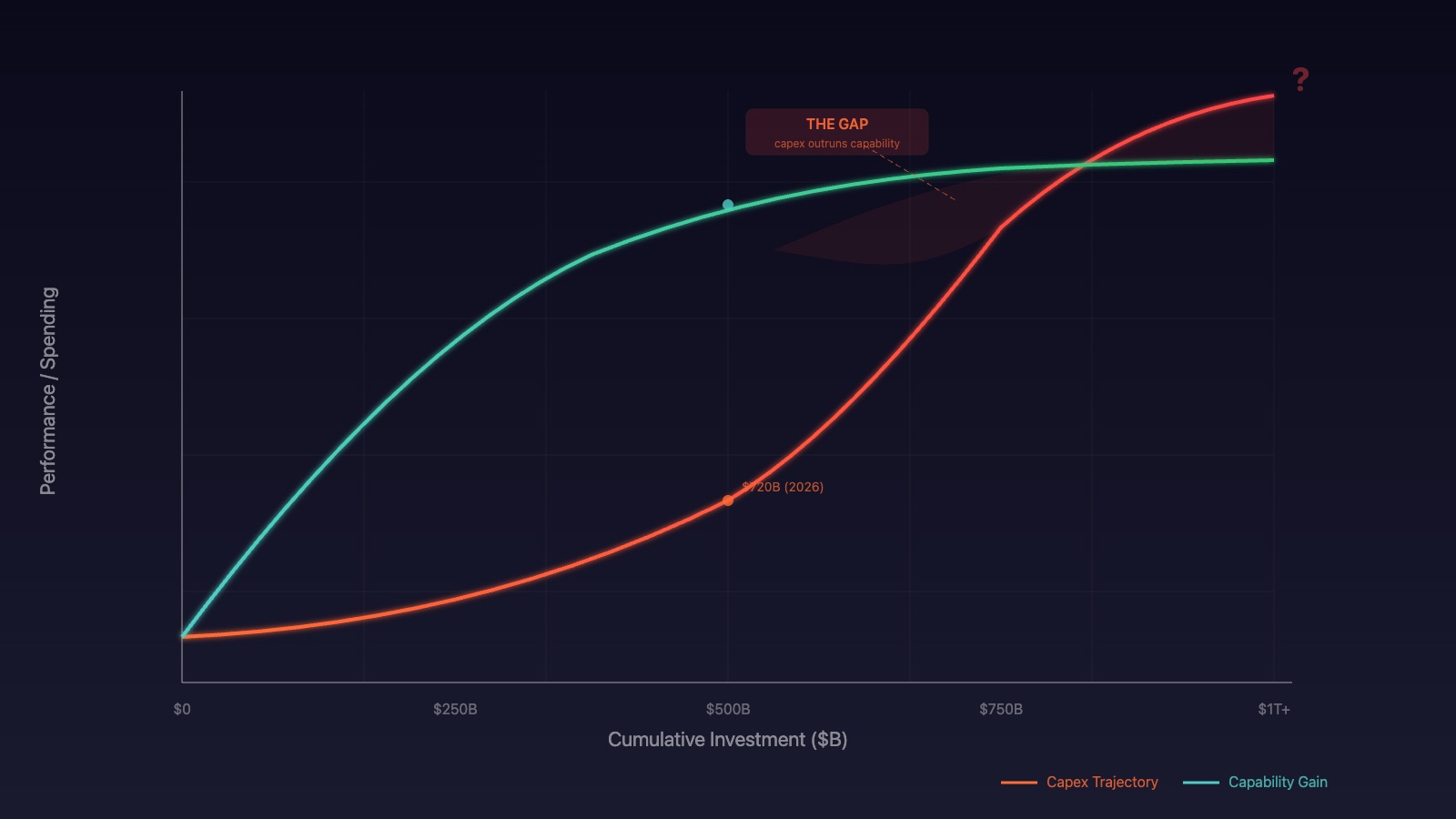
A recent paper by Chien-Ping Lu put it bluntly: "If AI scaling is to remain active, repeated efficiency doublings are not optional. They are required." The paper — titled Continued AI Scaling Requires Repeated Efficiency Doublings — argues that classical scaling laws remain predictive, but only if the efficiency stack keeps compounding. Without those doublings in hardware, algorithms, and systems, the capex curve outpaces capability gains. The math stops penciling out.
Meanwhile, TheAIGRID's viral video "The AI Scaling Law Might Be Breaking" put the anxiety in plain language for a half-million YouTube subscribers: medium-sized models are starting to beat large ones on emergent reasoning benchmarks. If you can get 80% of the capability at 10% of the compute, the economic case for the next $10 billion training run gets harder to make.
This is the quiet counter-narrative to the IPO euphoria. Four independent sources — YouTube AI, YouTube Tech, Substack, and X — all circled the same question in the same week. That convergence is itself the signal.
The Numbers: Where the Money Is Going
The scale is hard to overstate.
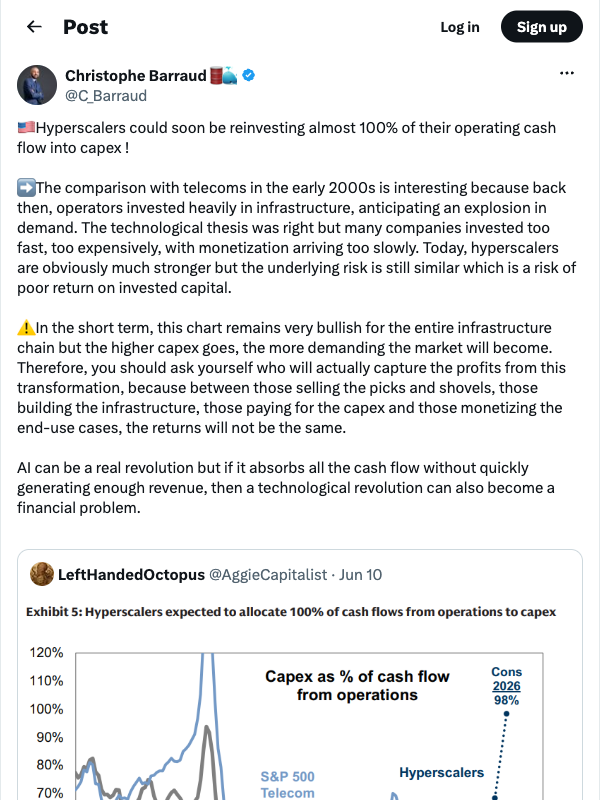
The top five U.S. hyperscalers — Microsoft, Alphabet, Meta, Amazon, and Oracle — are collectively projecting $720 billion in capital expenditures for 2026. That's up 77% from $410 billion in 2025, and it's the largest single-year concentrated infrastructure cycle in the history of technology. Not the internet. Not railroads. This.
Goldman Sachs's baseline model projects $765 billion in annual AI capex for 2026, growing to $1.6 trillion by 2031. Morgan Stanley goes higher, estimating Big Tech capex will surpass $800 billion this year alone.
But here's the part that matters: not all of that money is building the future.
The Motley Fool's analysis is instructive. Of the five major spenders, only Microsoft and Alphabet appear to be investing in genuine growth — reinforcing flywheels across data, customers, and distribution. The others may be spending simply to maintain relevance: buying infrastructure to ride the AI economy's rails rather than laying them.
Frontier training runs already cost approximately $500 million. Next-generation models are projected to require $1–10 billion. At some point, the question shifts from "can we afford to train?" to "can we afford not to question whether training is the right lever?"
T. Rowe Price estimates the cycle can persist for "another two to three years before facing its first true test." That framing is revealing: even the bulls are marking a deadline. This isn't open-ended optimism. It's a countdown.
Where Value Actually Lives (Hint: Not the Model)
The capex debate is really a proxy for a deeper question: if the models commoditize, who captures the value?
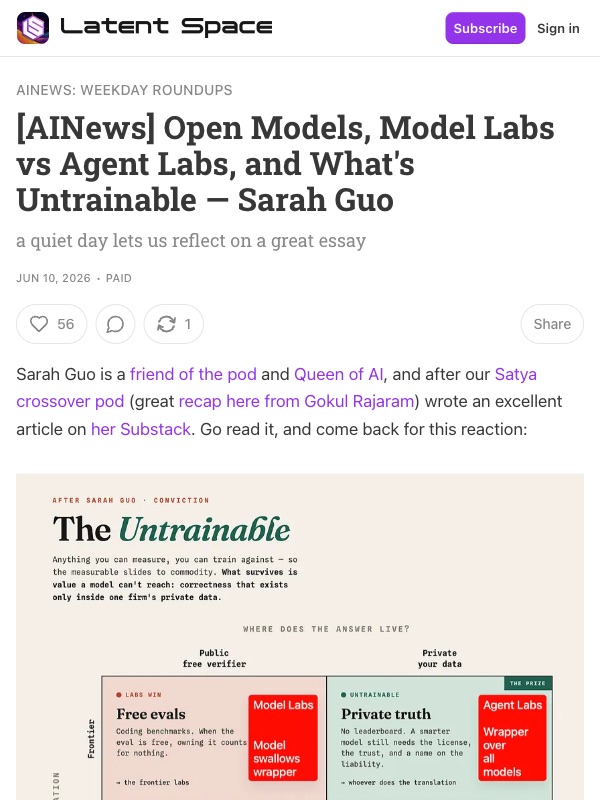
Sarah Guo's framework — published on Latent Space under the title "Model Labs vs Agent Labs, and What's Untrainable" — offers the sharpest answer. The winning companies aren't the ones training bigger models. They're the ones doing what she calls "unglamorous work: arranging a company's private reality so a model can act on it, handing the model the tools to act, working with the customer to change the reality of its workforce."
The key insight: intent is scarcer than compute. A model can execute, but it can't decide what's worth building. "You can't benchmark that," Guo writes, "so you can't train it."
Marc Andreessen echoed this at a16z's January 2026 LP meeting: "Foundation models are commoditizing fast. The moat is not the model — it is what you build around it." His advice to builders: "Do not rely on a single model."
Chamath Palihapitiya added the punchline: "AI is driving a 10x increase in the productivity of the individuals who know how to leverage it. But that's not enough. We've swapped the motor; we have not yet redesigned the factory." His deeper thesis in The Agentic AI Economy tracks the same migration: value commoditizes at the model layer and moves to application-specific orchestration.
If all three — Guo, Andreessen, Chamath — are saying the same thing, the market hasn't priced it yet. The $720 billion is flowing to the model layer, but the returns may accrue to the application layer. That gap is the risk.
For a related deep dive into the token economics driving this shift, see our earlier analysis: AI Token Economics: The Subsidy Clock Is Ticking.
The GDP Distortion Problem
Here's where the numbers get uncomfortable.
AI-related capital expenditure was responsible for 75% of Q1 2026 US GDP growth. Not 75% of tech-sector growth. Seventy-five percent of all economic growth. Strip out the AI buildout and the US economy was effectively flat.
David Sacks has framed this as bullish — AI driving the economy forward. But the Hacker News crowd sees it differently. In a front-page thread titled "AI capex is so big that it's affecting economic statistics," the top comments weren't celebrating. They were asking whether this is genuine investment or the new fiber-optic overbuild.

A follow-up thread — "AI is propping up the US economy" — pushed the concern further.
 The consensus: the AI buildout is the economy right now, and that's not a sign of strength. It's a dependency risk.
The consensus: the AI buildout is the economy right now, and that's not a sign of strength. It's a dependency risk.
At roughly 5% of US GDP, AI infrastructure spending in 2026 is the largest infrastructure commitment in modern economic history — 2.5× the fiber overbuild, 3× the electrification peak. The question isn't whether it's big. It's whether it's productive.
The uncomfortable parallel is obvious: the fiber-optic buildout of 1999–2001 was also "propping up" GDP growth right before the market corrected. That infrastructure turned out to be genuinely useful — just not at the valuations that funded it. The AI version could follow the same pattern: the infrastructure persists, the economics reset.
Alternative Paths (or: What If Bigger Isn't Better?)
The good news — if you can call it that — is that researchers aren't giving up on scaling. They're redefining it.

YC's Paper Club walked through five papers pointing to alternative scaling dimensions: AlphaZero-style self-play for language models, streaming RAG for real-time voice agents, formal verification with Lean. None of these require bigger models. They require smarter ones.
Cameron Wolfe's deep dive on scaling laws quantifies the diminishing returns. Knowledge tasks (like MMLU) show diminishing returns beyond 30 billion parameters. Reasoning tasks (like GSM8K) plateau around 70 billion. The curve isn't breaking — it's bending, and the bend point is lower than the industry's capex plans assume.
The Lu paper offers the technical framework: distinguish between "logical compute" (what the model actually needs) and physical compute (what you build to provide it). Scaling laws describe the former. The economics depend on the latter. Progress continues only if the efficiency stack — hardware, algorithms, systems — keeps compounding fast enough to make the physical cost tractable.
Test-time compute is the most visible alternative. Instead of training a bigger model, you let a smaller model think longer at inference time. Mixture of Experts (MoE) is another: train a large model but activate only a fraction of it per query. Synthetic data generation sidesteps the training-data bottleneck entirely.
These aren't moonshots. They're shipping. And they all share a common thesis: the next capability gain comes from spending compute differently, not spending more of it.
For a related look at how inference costs are already shifting the economics, see The Inference Inflection.
The Verdict: Two to Three Years to Prove It
The capex cycle isn't going to crash tomorrow. T. Rowe Price's "two to three years" is probably right as a floor. The hyperscalers are locked into power purchase agreements, data center builds, and custom silicon programs that take years to unwind. Even if the scaling returns flatten further, the spending has momentum.
But momentum is not a business case.
The tension is real and measurable: $720 billion flowing into the model layer the same week four independent sources question whether the model layer is where value will accrue. Goldman projects $1.6 trillion in annual AI capex by 2031 while researchers demonstrate that efficiency doublings — not raw compute — determine whether scaling remains economically viable.
The financing window is open. The IPO euphoria is real. But underneath it, the researchers are doing math that the markets haven't incorporated yet. Lu's paper says efficiency doublings are "not optional." Guo says intent is untrainable. Andreessen says the moat isn't the model. And three-quarters of US economic growth depends on none of them being right.
That's not a prediction of collapse. It's a description of a bet. The largest infrastructure bet in history, placed on a curve that might be bending.
The next two years will tell us whether we're building the internet — or laying fiber nobody will light.
For more on how Anthropic's IPO trajectory fits into this picture, see Anthropic's $965B Valuation: What the S-1 Numbers Actually Say.
ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
Join the discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related articles
His Duress PIN Wiped the Phone at the Border. It's a Felony.
A GrapheneOS duress PIN wiped a phone during a CBP search. The feds called it obstruction. What it means for your rights.
GPT-5.6 Closed a 30-Year Math Gap. Nobody Noticed.
A prompt-guided GPT-5.6 attack proved an optimal lower bound in convex optimization while coverage of the same model decayed into pricing tips.
Open Models Now Run 63% of AI's Token Traffic
Mozilla's data shows open-weight models flipped from 5% to majority token share in two years. What the cost curve means for your inference stack.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
WEEKLY. UNSUBSCRIBE ANYTIME.