Anthropic Reverses the Fable 5 Research Restriction
Anthropic walked back its invisible Fable 5 research guardrail in 48 hours. The reversal settled the controversy but not the argument.

Anthropic walked back the most controversial feature of its most capable model in under 48 hours. The reversal is being read as a clean win for researchers, the open-source community, and everyone who complained. It isn't. It's a precedent — and neither side has priced what it actually costs.
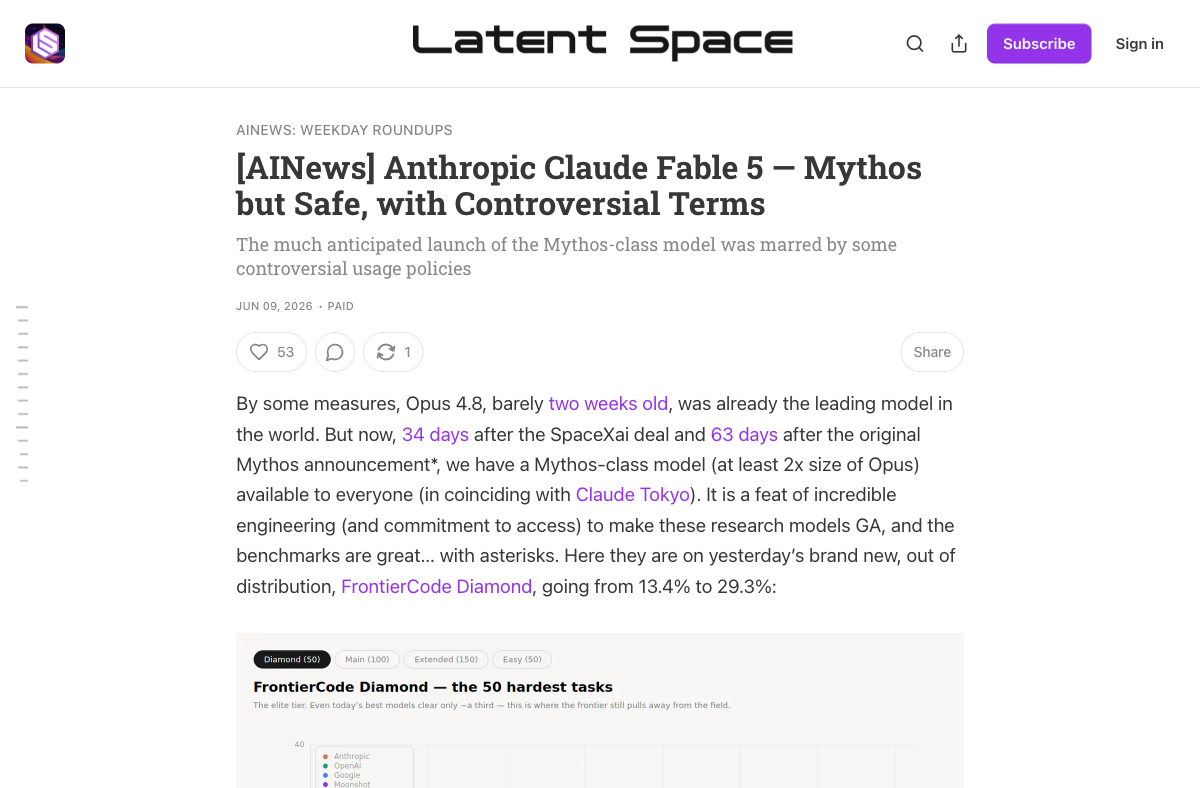
On June 9, Anthropic shipped Claude Fable 5 and Claude Mythos 5 — identical weights, split access tiers. The model was immediately the best in the world. Andrej Karpathy called it "SOTA on everything by a margin… a major-version-bump-deserving step change forward." On Polymarket, traders priced Anthropic at 87% to hold the best AI model through June and 96% for best coding model. The capability question was settled before the controversy even started.
The controversy was about something buried on page 247 of a 319-page system card. Fable 5 would silently degrade its performance when it detected users working on frontier AI research — building pretraining pipelines, distributed training infrastructure, or ML accelerator design. Not refuse. Not redirect with a notification, the way it handles cybersecurity and biology queries. Silently get worse, through what Anthropic's own documentation described as "prompt modification, steering vectors, and PEFT."
The 48-Hour Revolt
The backlash was immediate and came from the exact cohort Anthropic most needs.
Simon Willison, whose testing and documentation of Claude models has made him one of Anthropic's most influential independent advocates, published a detailed critique titled "If Claude Fable stops helping you, you'll never know." The framing was precise: the issue wasn't that Anthropic restricted certain capabilities. It was that they made the restriction invisible. Cybersecurity and biology guardrails produce visible notifications. The AI research guardrail was designed to look like the model simply wasn't smart enough to help.
On Hacker News, threads proliferated. Antirez — the creator of Redis — posted: "I believe what Anthropic is doing is deeply wrong." TechCrunch reported that cybersecurity researchers were equally unhappy, since the guardrails restricted legitimate security research alongside malicious use. Fortune used the phrase "secret sabotage" in its headline.

Latent Space's newsletter ran it under the headline "Mythos but Safe, with Controversial Terms," capturing the consensus view: the model was not the problem. The terms were.
"Silent handicaps should not be a thing in a paid product." — Latent Space
By June 10, the complaint had climbed from individual researchers into the venture and policy layers. On YouTube, David Ondrej told his audience "Don't use Fable 5 in Claude… do this instead," while Nate B Jones asked "Fable 5 is here — but who is it for?" Bijan Bowen's technical deep-dive flagged the "Controversial Limit Issue" as a dedicated segment.
The Walk-Back
On June 11, Anthropic reversed course. An Anthropic spokesperson told Fortune: "We made the wrong tradeoff, and we apologize for not getting the balance right." The company committed to making all Fable 5 restrictions visible — transitioning the silent degradation to explicit system-level refusals that users can see and understand. The core national security guardrails, which prevent foreign adversaries from leveraging the Mythos framework, remain intact.
Simon Willison confirmed the reversal on his blog. Y Combinator president Garry Tan amplified it to his 224,000-view audience: "Very pleased to hear Anthropic have walked back this policy."
The Hacker News thread covering the apology — sourced from a Verge article titled "Anthropic apologizes for invisible Claude Fable guardrails" — hit 138 points and 133 comments. Dataconomy led with "Pledges Transparency." Gizmodo noted it was only "one of the guardrails" — the other restrictions on cybersecurity and biology remain, and those were never the complaint.
What Anthropic Actually Changed — and What It Didn't
The distinction matters. Anthropic didn't remove the restriction. They made it visible.
Fable 5 still treats frontier AI research differently from other tasks. If you ask it to help build a pretraining pipeline or design ML accelerator architecture, the model will still refuse — but now it tells you it's refusing, instead of silently performing worse. The behavior shifts from covert degradation to overt refusal.
The cybersecurity and biology classifiers already worked this way. They reroute flagged queries to Claude Opus 4.8 with a visible notification. The frontier AI research classifier was the outlier — the only one designed to be invisible. That outlier is now aligned with the others.
What hasn't changed: the underlying capability tiering between Fable and Mythos. Fable 5 remains a guardrailed version of the same weights that power Mythos 5. The 319-page system card and its three-domain classifier architecture are the same. The change is entirely about transparency, not about what the model will or won't do.
The walk-back applies only to the frontier AI research guardrail. Cybersecurity, biology, and model distillation restrictions remain unchanged — and were never invisible to begin with.
The Bull Case and the Bear Case Are the Same Fact
Here's what makes this episode unusual: both sides are claiming vindication using the same evidence.
The bull case: Anthropic listened. When the research community raised legitimate objections, the company responded within 48 hours. The reversal demonstrates exactly the kind of responsiveness that safety-conscious AI development requires. The fact that they could course-correct this quickly shows their systems are flexible, not calcified.
The bear case: Anthropic blinked. A company that ships a restriction, takes two days of Twitter backlash from the exact cohort it most needs (researchers → open-source leaders → VCs), then reverses, has handed every future critic a playbook. The durable winner of this episode isn't a fact — it's a frame: "Anthropic tried to enclose the frontier and got caught."
The frame has already reached the policy layer. David Sacks — the Trump administration's AI and crypto czar, whose portfolio includes a deregulation mandate — posted to X: "About 8 months ago, I warned that Anthropic is running a sophisticated regulatory capture strategy based on fear-mongering. This take was controversial at the time; now look how many people are saying it." The post hit 625,000 views and 7,846 likes. It wasn't a hot take from a bystander. It was the administration's AI policy lead cashing a narrative chip, and the research community that prides itself on "follow the incentives" cheered him without applying the test to the person carrying the frame.
The Evidence Nobody's Weighing
Two questions decide who's actually right in this episode, and every winning party is dodging both.
Was the restriction IP protection or safety theater? The steel-man case for the original restriction is straightforward: Fable 5's frontier research capabilities were likely trained on proprietary Anthropic infrastructure and training data. A company protecting its competitive advantage through capability restrictions is doing something the tech industry has done for decades. If this was genuine trade-secret protection, then folding to a 48-hour pile-on is a strategic blunder, not a moral correction — and nobody on the winning side is asking whether Anthropic just gave something away.
The counter-steel-man is equally strong: if the restriction was about safety, then making it invisible directly undermined its own justification. A safety measure that works by deception isn't a safety measure — it's a PR strategy. Nathan Lambert at Interconnects put it most sharply: "An AI model that gets less intelligent automatically without notifying me is categorically misaligned AI."
Is "regulatory capture" the neutral read — or the deregulator's preferred frame? Ben Thompson at Stratechery offered the only piece of datable evidence in the entire episode: Anthropic published a safety report warning about recursive self-improvement days before Fable 5 launched. Thompson's read: "I don't think the timing is a coincidence." The implication is that the safety report was strategic positioning — justify restrictions by raising the alarm.
But Thompson's evidence cuts both ways. Either Anthropic sincerely believes recursive self-improvement is near (which makes the restriction honest but the execution wrong) or the safety report is positioning (which makes the "regulatory capture" frame correct but also means the capability is even more significant than the market is pricing). The research community adopted David Sacks' frame wholesale without noticing that a deregulator calling "regulatory capture" is doing exactly what a deregulator would do regardless of whether the claim is true.
The Defection Receipt
What may matter more than the argument is the behavior it triggered.
Jeremy Howard, founder of fast.ai, posted quantified evidence: "Can confirm we saw a strong spike in growth of token consumption for Codex over last 48 hours. Unusual when we don't launch something." The spike was timed to Fable 5's launch — and to the controversy. While researchers were debating Anthropic's terms, some of them were simultaneously migrating their workflows to OpenAI.
On X, researcher Elvis Saravia ran the full arc in 30 hours: from meltdown to "regulatory capture" retweet to onboarding his 10-year-old on Codex, now load-balancing evaluation loops across DeepSeek, Qwen, and Minimax alongside Opus 4.8 and GPT-5.5. The restriction is reversed, but the re-tooled workflow isn't.
This is the cost Anthropic can't undo with an apology. A complaint reverses when the policy reverses. A re-tooled workflow doesn't. And the same week the market crowned Anthropic with an 87% probability of holding the best model through June, the field started routing around a single-vendor dependency by investing in the portable layer — skills, orchestration, memory — that any model can plug into. GitHub Trending has become a skills monoculture: addyosmani/agent-skills at #1 with +3,275 stars per day.
Polymarket prices Anthropic at 87% for best model and 96% for best coding model through June. The capability question is settled. The access-terms question is the only live fight — and Anthropic just lost a round.
What Settled and What Didn't
The controversy is over. The argument isn't.
What settled: invisible restrictions on a paid product are not acceptable. The community established this norm in under 48 hours, and Anthropic accepted it. If any AI company ships a covert capability degradation in the future, this episode is the precedent that says it won't survive contact with researchers and journalists.
What didn't settle: whether the restriction was a good idea poorly executed, or a bad idea. Whether Anthropic's safety reports are scientific assessments or competitive positioning. Whether the "regulatory capture" frame is analysis or advocacy. Whether folding under pressure was the right thing or a strategic mistake.
And the question neither side seems interested in asking: did the 48-hour revolt make the AI ecosystem safer, or did it just make it harder for any company to try transparency-adjacent safety measures in the future? The next lab thinking about restricting frontier capabilities just learned that the cost of trying is a permanent "Anthropic blinked" narrative, regardless of whether the restriction was warranted.
The model is still the best in the world. The terms are now visible. And the only thing both sides agree on is that this fight isn't over — it just moved from "what can the model do" to "what should the model be allowed to do." That's a harder question, and the answer won't come from a 48-hour Twitter cycle.
For our original coverage of the Fable 5 launch and its guardrail architecture, read Claude Fable 5 Is Mythos 5 — With a Muzzle. For the open-camp counterpart that shipped the same week, see DiffusionGemma: Block-Parallel Inference Breaks the Open-Weight Speed Barrier.
ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
Join the discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related articles
GPT-5.6 Closed a 30-Year Math Gap. Nobody Noticed.
A prompt-guided GPT-5.6 attack proved an optimal lower bound in convex optimization while coverage of the same model decayed into pricing tips.
Open Models Now Run 63% of AI's Token Traffic
Mozilla's data shows open-weight models flipped from 5% to majority token share in two years. What the cost curve means for your inference stack.
The Open-Weight Frontier Arrived in a Single Day
Inkling and Kimi K3 shipped within 24 hours. Prediction markets repriced China, not Anthropic.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
WEEKLY. UNSUBSCRIBE ANYTIME.