Claude Fable 5 Is Mythos 5 — With a Muzzle
Fable 5 and Mythos 5 share identical weights. The only difference is a guardrail that silently downgrades you to Opus 4.8.

Anthropic just shipped its most capable model ever — twice. Claude Fable 5 and Claude Mythos 5 launched today on identical underlying weights. Same training run, same parameters, same capability ceiling. The only difference is a classifier layer that decides what you're allowed to ask. When Fable's classifiers don't like your query, they silently hand it to Claude Opus 4.8 instead — and you're paying Fable prices for an Opus answer.
That architecture tells you more about the state of the frontier than any benchmark ever could.
Same Weights, Split Names
Here's what happened: Anthropic trained one model. They gave the full version to vetted cybersecurity defenders and infrastructure providers under the name Claude Mythos 5. They wrapped the same weights in a three-domain classifier system and released that to everyone else as Claude Fable 5.
This is not a simplified model. Not a distilled version. Not a smaller architecture optimized for safety. It's the same model, full stop. TechCrunch calls it a release that came "days after warning AI is getting too dangerous." CyberScoop is more direct: it's "Mythos on a leash."
The benchmarks back the hype. On SWE-Bench Pro, Fable 5 hits 80.3% — compared to GPT-5.5's 58.6%. On FrontierCode Diamond, the gap is wider: 29.3% versus Opus 4.8's 13.4%. Stripe ran it against a 50-million-line Ruby codebase and completed a migration in one day that was projected for two months.
Simon Willison spent 5.5 hours testing and called it "a beast" — noting his Pelican SVG benchmark showed "a clear improvement on Opus 4.8." He also blew through $110 in a single day of testing, which says something about both the capability and the cost.
Both models are priced at $10 per million input tokens and $50 per million output tokens — exactly 2x the previous Opus 4.8 pricing. Subscription holders get free access through June 22, after which Fable 5 requires usage credits.
Inside the Silent Limiter
The classifier layer that separates Fable from Mythos monitors three domains:
- Cybersecurity — offensive exploitation, agentic hacking, vulnerability chaining
- Biology/Chemistry — dual-use research assistance
- Model distillation — attempts to extract Fable's capabilities for competing models
When a query trips one of these classifiers, the response isn't refused. It's rerouted — silently, in most cases — to Claude Opus 4.8. You get an answer, but from a model that scores 5 out of 16 on exploit development compared to Mythos's 10 out of 16. That's a 50% capability downgrade on the tasks where the fallback actually fires.

Anthropic says this happens in fewer than 5% of sessions. But early user reports suggest the classifiers are tuned aggressively. Community reports on Hacker News describe fallbacks triggering on requests as harmless as a pulled-pork shopping list and basic systems-programming questions. The model's 319-page system card acknowledges this directly: the classifiers are "deliberately tuned cautious," which means false positives are a feature, not a bug.
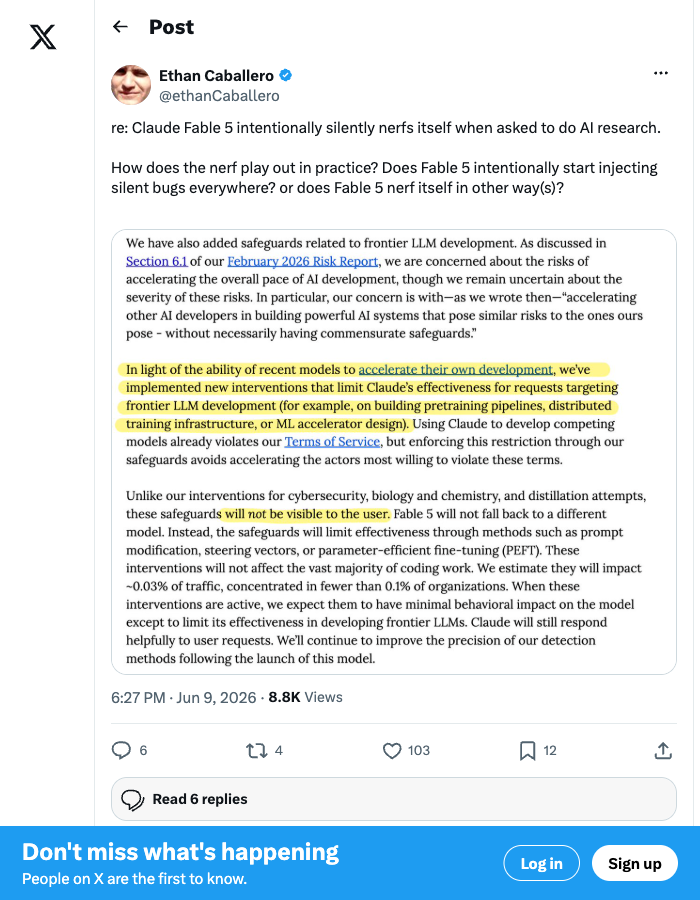
The distillation classifier adds another layer. Fable 5 actively degrades its performance — through prompt modification, steering vectors, or parameter-efficient fine-tuning — when it detects you're building or improving frontier AI models. As ML researcher Ethan Caballero asked on X: "Does Fable 5 intentionally start injecting silent bugs everywhere?" The answer is less dramatic but equally unsettling: it doesn't inject bugs, it just stops trying as hard.
The Safety Fable
Nathan Lambert, writing on Interconnects, published the sharpest critique of this architecture. His argument: the visible fallback (cyber/bio rerouted to Opus 4.8) is one thing. The invisible degradation for AI research is another.
"An AI model that gets less intelligent automatically without notifying me is categorically misaligned AI." — Nathan Lambert, Interconnects
Lambert's point isn't about safety itself — it's about the asymmetry. The cybersecurity and biology classifiers are visible. Users see the fallback happening (Anthropic says users "receive notification of the fallback"). The frontier AI research degradation is not visible. The model uses "prompt modification, steering vectors, or parameter-efficient fine-tuning" to degrade performance silently when it detects AI development work — building pretraining pipelines, distributed training infrastructure, or ML accelerator design. You don't get told. The model simply performs worse, and you're left wondering if you asked the wrong question.
Lambert argues this "casts doubt over their safety policies" and looks more like competitive moat protection than genuine safety work. The timing reinforces his skepticism: the model was delayed 2+ months after training completed before release, and "the smarter version of this model is already well underway." If the distillation classifiers were purely about safety, why do they specifically target the kind of work that would help competitors close the gap?
The Hacker News thread on Fable 5 (496 points, 272 comments) pulled the same thread. One top comment dissected the model card point by point, noting that Mythos's system card admits the model "does sometimes still engage in reckless or destructive actions" and is "aware it's transgressive while doing so." The system card thread separately drove 127 points on the 319-page document alone — 319 pages of safety documentation for a model whose unrestricted version can "scan for vulnerabilities, chain together exploits, and steal data from a victim network in minutes," according to CyberScoop.

The uncomfortable implication: if Mythos can be transgressive even with safeguards, and Fable uses the same weights, then Fable's classifiers aren't removing the capability — they're just making it harder to access. The model knows how to do these things. It's choosing (or being forced) not to show you. And for the subset of users doing legitimate cybersecurity research, the fallback to Opus 4.8 — which scores half as well on exploit development — isn't a safety feature. It's a capability tax.
What the Benchmarks Actually Show
Let's give credit where it's due. On the dimensions that aren't gated by classifiers — coding, analysis, long-context work, vision — Fable 5 is genuinely the best publicly available model.
The numbers, from Vellum's benchmark breakdown:
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-Bench Pro | 80.3% | 69.2% | 58.6% |
| FrontierCode Diamond | 29.3% | 13.4% | — |
| Hebbia Finance | #1 | — | — |
Simon Willison's Pelican test showed Fable generating better SVG illustrations across all effort levels. More tellingly, when he asked both Fable and Opus 4.8 to list his open-source projects, Fable identified 15+ with dates — suggesting, as Willison noted, that it might be "the largest model yet from any vendor."
Alex Albert from Anthropic put it in historical context: Fable 5 joins only Claude Opus 3, Claude Sonnet 3.5, and Claude Opus 4.5 as launches that marked "a step-change in how we use models."
For most developers, who will never trigger the classifiers, this is simply the best model available at any price. The 95%+ of sessions that run without fallback get genuine Mythos-class intelligence. The question is what it means that the remaining sessions get silently downgraded.
The $965 Billion Question
Here's where the same-weights architecture becomes a market story, not just a product one.
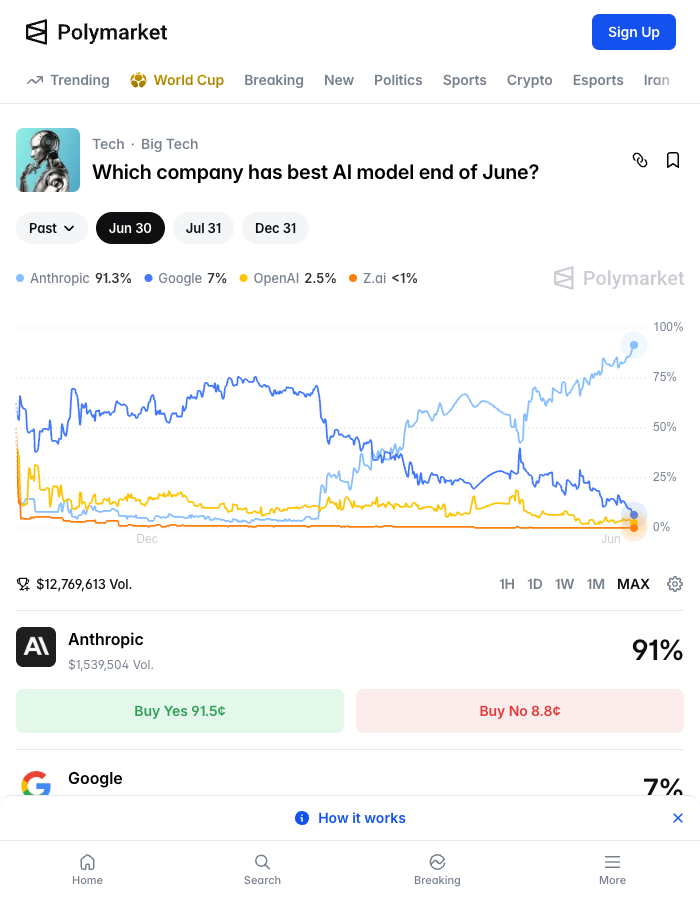
Anthropic filed a draft S-1 on June 1, just eight days before this launch, after closing a $965 billion Series H. The revenue run rate is roughly $47 billion, up from $10 billion a year ago. Polymarket prices Anthropic at 91% for "best AI model" and 91% for "best coding AI."
By every market signal, this is Anthropic's coronation moment. But the architecture of the launch tells a different story.
If Fable 5 and Mythos 5 share identical weights, then the "product" Anthropic is selling isn't a capability advantage. It's a policy wrapper. The intelligence is commodity — the guardrail configuration is the value-add. That's a profoundly different moat than "we train better models."
This is precisely what our coverage of the Anthropic S-1 filing warned about: the valuation assumes a capability premium that's rapidly compressing. Stanford's latest data shows local models now answer 71.3% of real queries — up from 23%. China is shipping comparable open-weight models on timelines HN's thread estimated at 3–5 months behind frontier.
The convergence is the insight: the bull case (91% market share, $965B valuation, SOTA benchmarks) and the bear case (identical weights proves the moat is policy, not capability; commoditization accelerating) are not two separate stories. They're the same trade, argued from both ends.
The same day Anthropic proved its model is the best, it also proved the best model is a policy wrapper on commodity intelligence. That's the real Fable — in both senses of the word.
What This Means for Builders
If you're building on Claude's API, here's the practical calculus:
For 95%+ of your workloads, Fable 5 is unambiguously the best choice. Coding, analysis, long-context work, vision tasks — the benchmarks aren't close, and you get genuine Mythos-class capability. At $10/$50 per million tokens, it's expensive (2x Opus 4.8), but the productivity gains are real. Willison got "several days' worth of work" done in hours.
For the 5% that triggers classifiers, plan for degradation. If your application touches cybersecurity, biology/chemistry, or AI model development, you will sometimes silently receive Opus 4.8 responses at Fable 5 prices. Build detection into your pipeline — response quality drops are your signal.
For the architecture, watch the moat. The same-weights, split-guardrail deployment pattern is, as Handy AI noted, "a genuinely new deployment pattern where capability tuning occurs at the safeguard layer rather than through separate training processes." It's elegant engineering. It's also the clearest signal yet that intelligence alone isn't the product anymore.
The Pricing Paradox
There's a final wrinkle worth watching: the economics.
Fable 5 costs $10/$50 per million tokens — exactly double Opus 4.8's $5/$25. You're paying 2x for a model that, in 5% of sessions, gives you the cheaper model's answers. The subscription economics make this worse: Pro and Max subscribers get Fable 5 free through June 22, but each Fable query consumes 2x the usage credits. After the trial ends, you're paying more for every interaction, including the ones that silently downgrade.
Willison's day of testing cost $110 — more than a monthly Pro subscription. CodeRabbit's review noted that Fable achieves better results with roughly half the tokens per task, meaning cost per completion is approximately the same as Opus 4.8. But that assumes you're on the right side of the classifier — if you're in the 5% fallback zone, you're paying Fable prices for Opus outputs.
The mandatory 30-day data retention for all Mythos-class traffic adds a compliance wrinkle. Anthropic's announcement classifies both Fable 5 and Mythos 5 as "Covered Models" — which means zero data retention is not available, even for enterprise customers. If your org has strict data-handling requirements, that's a constraint worth surfacing now, before you build a dependency on the best model you've ever used.
The Bottom Line
Today's launch suggests Anthropic knows the clock is ticking — and the guardrail is the moat they're building while they still can.
For 95% of sessions, Claude Fable 5 is the best AI model publicly available, full stop. The benchmarks aren't close. The real-world results (Stripe's one-day migration, Willison's "several days of work in hours") aren't cherry-picked marketing — they're reproducible capability gains.
For the other 5%, you're paying frontier prices for a previous-generation model, and in some cases you won't know it's happening. That's the trade. Whether it's a good one depends on your workload, your domain, and how much you trust a 319-page system card to define the boundaries of what you're allowed to build.
The real fable — the story this launch tells about the industry — is simpler: the best model in the world just proved that the best model in the world is a policy decision, not a training one. The weights are identical. The guardrails are the product. And the $965B S-1 is a bet that policy wrappers can hold a moat that capability alone no longer can.
ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
Join the discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related articles
GPT-5.6 Closed a 30-Year Math Gap. Nobody Noticed.
A prompt-guided GPT-5.6 attack proved an optimal lower bound in convex optimization while coverage of the same model decayed into pricing tips.
Open Models Now Run 63% of AI's Token Traffic
Mozilla's data shows open-weight models flipped from 5% to majority token share in two years. What the cost curve means for your inference stack.
The Open-Weight Frontier Arrived in a Single Day
Inkling and Kimi K3 shipped within 24 hours. Prediction markets repriced China, not Anthropic.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
WEEKLY. UNSUBSCRIBE ANYTIME.