Harness Leaderboards Are the New Model Leaderboards
Dirac took Gemini 3 Flash from 47.8% to 65.2% on TerminalBench — a +17pp swing from harness alone. Why model leaderboards miss the real story.

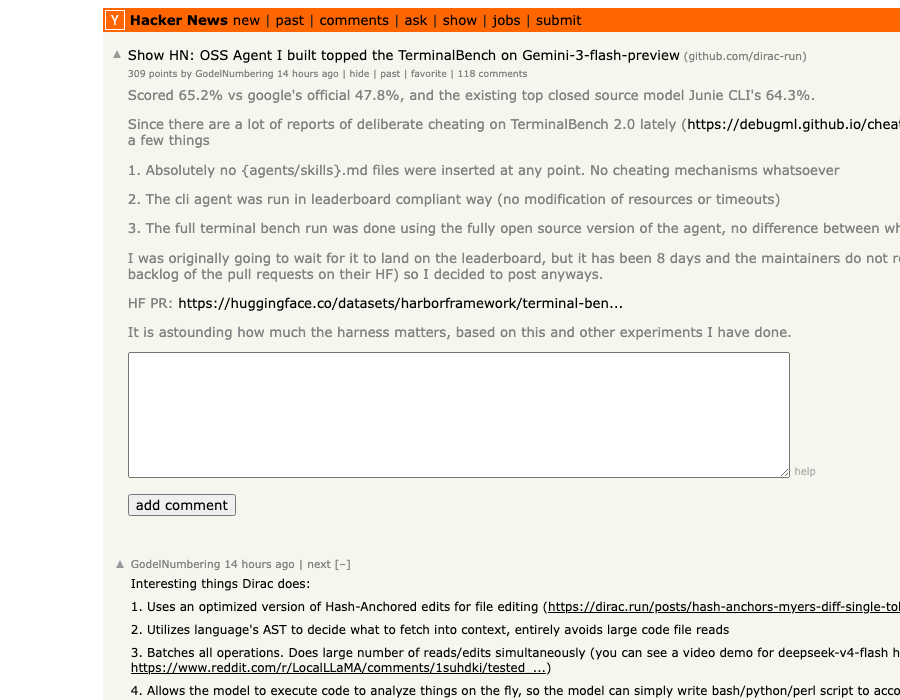
Two days ago, an open-source coding agent called Dirac landed at the top of the Terminal-Bench 2.0 leaderboard on Gemini 3 Flash Preview. Its score: 65.2%. Google's own official run on the same model: 47.8%. The previous best closed-source agent on Gemini 3 Flash, JetBrains' Junie CLI: 64.3%.
Same model. Same benchmark. +17.4 percentage points over Google's own baseline, from harness work alone.
The Show HN thread hit 309 points in 12 hours — and the conversation underneath it crystallized something the AI engineering community has been circling for months: the model leaderboards we keep refreshing are measuring the wrong thing. What you actually want — but can't find anywhere — is a harness leaderboard. A scoreboard for the scaffolding that wraps the model.
📖 This is the practitioner sequel to our March deep-dive on why harness engineering matters more than your model. If you skipped that one, this article will make more sense after a quick read.
The Result That Should Reshape How You Pick Tools
Let's start with the numbers, because they're the entire story.
| Agent / Harness | Model | Terminal-Bench 2.0 | Cost vs. Dirac |
|---|---|---|---|
| Dirac (open source) | Gemini 3 Flash Preview | 65.2% | 1.0x (baseline) |
| Junie CLI (JetBrains) | Gemini 3 Flash Preview | 64.3% | ~2.8x |
| Google official run | Gemini 3 Flash Preview | 47.8% | — |
| Codex CLI | GPT-5.5 | 82.0% | (different model) |
| ForgeCode | Claude Opus 4.6 | 79.8% | (different model) |
| ForgeCode | GPT-5.4 | 81.8% | (different model) |
| ForgeCode | Gemini 3.1 Pro | 78.4% | (different model) |
Two patterns jump out of that table.
First, the +17.4pp gap between Dirac and Google's own number on the same model. That isn't a measurement artifact. The TerminalBench team and the Hugging Face leaderboard verification thread confirmed Dirac's run was leaderboard-compliant — no benchmark-specific files, no skills/agents.md cheating, all open-source code matching the public repo.
Second, look at the ForgeCode rows. The same harness — ForgeCode — appears three times in the top 10, with three completely different models (Opus 4.6, GPT-5.4, Gemini 3.1 Pro), within a 4pp band of each other. The harness is the constant. The model is the variable. And the harness is what's keeping the score above 78% no matter which model you plug in.
This is the empirical case for what people have started calling harness engineering — and the reason why "GPT vs Claude vs Gemini" has become an increasingly stupid question. The right question is: which harness are you running them in?
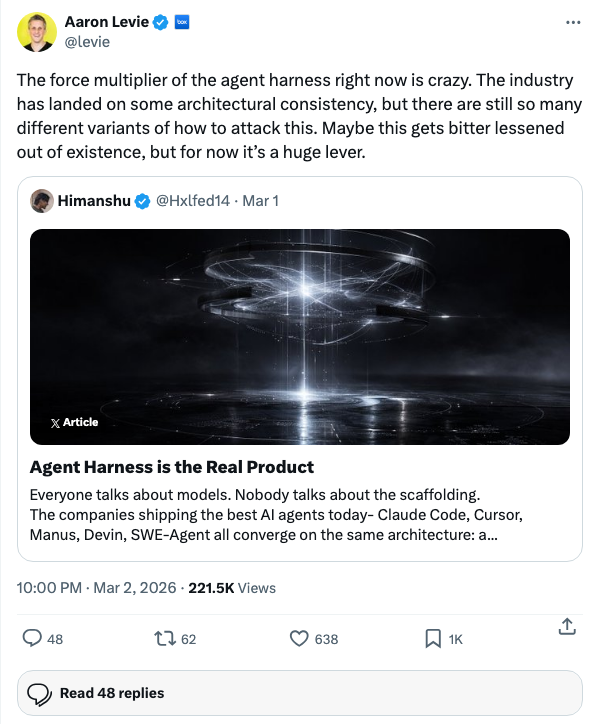
Aaron Levie has been calling this for six months. He's right. Until — as he puts it — the bitter lesson eats the harness, the harness is the lever.
What Dirac Actually Changed
If you read the Dirac README at face value, the optimization list reads like generic agent-engineering buzzwords. The interesting part is why each choice exists, because each one targets a known failure mode in how LLMs interact with code.
1. Hash-Anchored Edits (instead of search-and-replace)
The default file-editing primitive in most coding agents is some flavor of str_replace: the model writes "find this exact string, replace it with this one." This breaks constantly. Whitespace mismatches. Repeated lines. The model writing a slightly-paraphrased version of the line it claims to be matching.
Dirac replaces this with hash-anchored edits: every line in the file is hashed, and the model targets edits by line hash, not by reproducing the line text. The hash format looks roughly like this in the tool call:
edit:
file: src/auth/middleware.ts
anchor: a3f7e2 # hash of the line we're editing
context_above: 8b1c4d
context_below: e9f0a2
new_lines:
- " if (!token || isExpired(token)) {"
- " return res.status(401).json({ error: 'unauthorized' });"
- " }"
The model never has to recite the line back. It just points. This is exactly the technique the can.ac post that hit 832 points on HN generalized to 15 different LLMs, finding ~20% token reduction and +5-14pp on editing benchmarks across every model tested. It works on weak models. It works on strong models. The harness does the work.
2. AST-Aware Context Fetching (instead of full-file reads)
The second big lever: don't read the file. Use the language's syntax tree to fetch only the symbols the agent actually needs.
If the agent wants to modify a validateToken function, it doesn't get the 800-line auth.ts file dumped into context. It gets the function body, its imports, and its callers — extracted via Tree-sitter or a language server. The Dirac README claims this "entirely avoids large code file reads" and prevents what the author calls bundled package pollution — the situation where some node_modules import drags 4,000 tokens of vendored code into the model's context window.
The downstream effect: smaller prompts, lower cost, and — counterintuitively — better accuracy. Models with full files in context tend to wander; models with surgical context stay on task. This is the part that explains the 50-80% cost reduction in Dirac's evaluation table. You're not just saving money; you're feeding the model less noise.
3. Batched Tool Calls (instead of sequential)
Dirac's tools accept lists. Instead of "read file A, wait, read file B, wait, read file C, wait," the model issues read_files: [A, B, C] in a single round-trip. Same for edits, same for searches.
This sounds trivial. It isn't. Most models are reluctant to issue parallel tool calls — they default to one-at-a-time even when the harness allows parallelism. Dirac's tool schemas force the issue by making list parameters the only option for batchable operations. The model can't not batch.
The author noted in the HN discussion that this single change cut wall-clock time per task by roughly 40% with no accuracy loss.
The Anthropic Confession
If you needed more evidence that harnesses are doing real work, Anthropic gave it to us yesterday — by accident.
For three weeks (March 26 to April 10), Claude Code users were complaining that Sonnet had "gotten dumber." Yesterday, Anthropic's developer team confirmed the cause:
Two specific changes did the damage, per Anthropic engineer Viv Trivedy:
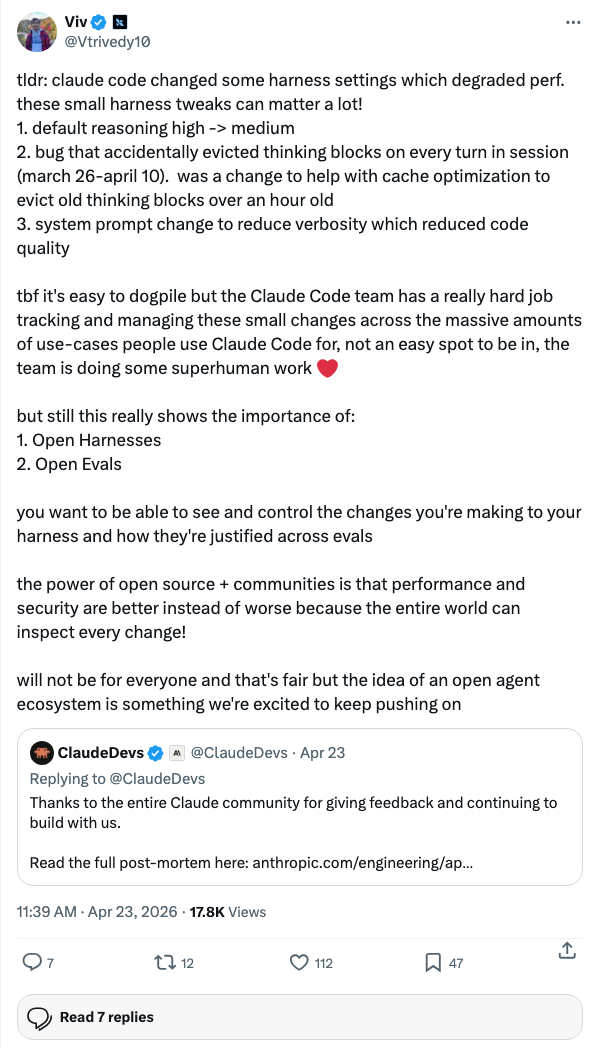
Read that carefully. The model didn't change. The API didn't change. Two harness settings — a reasoning-effort default and a thinking-block eviction bug — produced three weeks of perceived intelligence regression across thousands of paying developers. Anthropic itself is now telling you that "small harness tweaks can matter a lot."
This is the same lesson Dirac is teaching, just from the opposite direction. Dirac shows that harness work can add 17 points to a score. The Claude Code regression shows that harness work can subtract enough to make a top-tier model feel broken. The model is necessary. The harness is decisive.
Tendril and the Other Half of the Argument
Dirac wasn't the only harness story on the HN front page that day. Position #7 was Tendril — a self-extending agent that builds and registers its own tools across sessions. Different angle, same underlying claim.
Tendril's framing nails the problem:
"Agent frameworks give you what a tool does and how to call it, but no structured answer to when — when should a tool fire autonomously."
Tendril's bet: instead of giving the model a fixed toolbox of 50 hand-written tools, give it three bootstrap tools and let it write its own. After enough sessions, the agent has accumulated a project-specific tool registry that's tuned to this codebase, this deployment, this team's habits. The tool surface stays at three. The capabilities behind that surface grow indefinitely.
The honesty in the Tendril README is what makes it interesting: it doesn't work on weak models. The author tested Qwen3, Gemma 4, Mistral, and two others — all five failed. Only Claude Sonnet 4.5 succeeded. That's a real signal. Tendril's harness is demanding, but when paired with a strong model, it produces compounding capability over time. That's a different optimization frontier than Dirac's "make any model better at TerminalBench" — but it's the same thesis applied to a different axis.
The Skills Directory Boom
The third data point from this week: Matt Pocock's mattpocock/skills repository — a curated collection of 21 Claude Code skills covering TDD, planning, code review, and git safety — added 5,551 stars on day three of its release wave. It's now sitting at 31,000 stars with 2,400 forks. (We covered the broader skill-sharing trend last month.)
Why does this matter for the harness conversation? Because skills are harness components. A tdd skill isn't a model upgrade — it's a packaged behavior pattern that constrains how the model approaches a coding task. A git-safety skill isn't a tool — it's a guardrail. When 31,000 developers star a skills repo in three weeks, that's the market voting that the harness layer is where the marginal improvement lives.
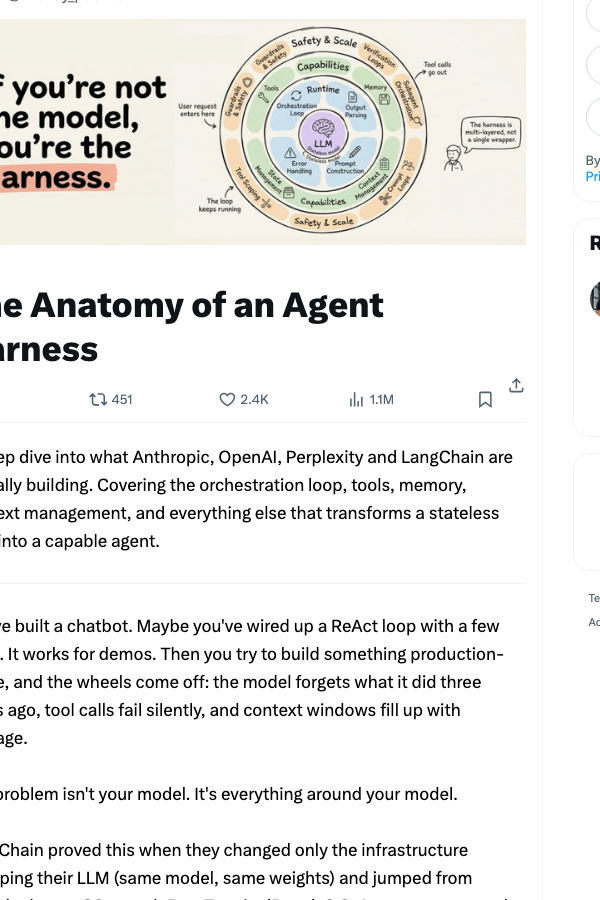
Why Harness Leaderboards Don't Exist Yet (And Why That's the Bug)
If harnesses matter this much, why is there no public leaderboard ranking them?
Three reasons, all soluble:
-
Benchmarks are model-shaped. Terminal-Bench 2.0, SWE-Bench, HumanEval — they all advertise scores by model name first, harness as parenthetical. Look at how the public dashboards format their entries: "Codex (GPT-5.5) 82.0%" — the harness is in parens, like an afterthought. We need the inverse: "GPT-5.5 (Codex) 82.0%" with a separate "harnesses" tab that holds model fixed and varies the wrapper.
-
Harnesses don't have stable identities. A "Dirac" run today isn't a "Dirac" run six weeks from now — the prompts change, tool schemas evolve, the README updates. Versioning a harness for benchmarking purposes is harder than versioning a model checkpoint, and nobody's done the standardization work.
-
The vendors don't want it. A harness leaderboard makes the model's contribution look smaller. Anthropic, OpenAI, and Google all benefit from the current framing where "GPT-5.5 leads at 82%" is the headline. None of them want a leaderboard that reads "Codex harness adds X points to whichever model you plug into it."
But the demand is there. Look at how the Terminal-Bench 2.0 leaderboard is actually being used in practice: developers aren't picking models, they're picking agent-model pairs. When ForgeCode appears three times in the top 10 with three different models, you're already looking at a harness leaderboard with the labels in the wrong order.
How to Actually Pick (or Build) a Harness
Until somebody ships a public harness leaderboard, here's the practical decision framework:
1. Start with what's in your daily loop. If you live in a JetBrains IDE, Junie CLI is already wired in and gets you to 64% on TerminalBench-style work. If you live in the terminal, Codex/Claude Code/Dirac are your candidates. Match the harness to the surface you actually use — switching surfaces is more expensive than the score gap.
2. Look at the cost-per-task column, not the accuracy column. Dirac is on top of the leaderboard for Gemini 3 Flash, but the more interesting number in its table is 2.8x cheaper than Junie CLI for the same task. Over a year of agentic work, that's the difference between a $200/month bill and a $560/month bill. Harnesses optimize cost, not just accuracy. Pay attention to both axes.
3. Audit the three things Dirac taught us to look for:
- Does the harness use hash-anchored or line-number-anchored edits? (Anything else is a downgrade.)
- Does it do AST-aware or full-file context fetching? (Full-file is wasteful and noisy.)
- Does it issue batched or sequential tool calls? (Sequential is leaving 30-40% latency on the floor.)
4. If you're rolling your own: start with the can.ac harness post and the open-source Dirac README. Both are short, both are concrete, both contain transferable techniques you can graft onto any agent loop. You don't need to fork Cline — you need to copy the patterns.
5. Watch for the next consolidation. OpenAI killed the Codex model line yesterday — there's no gpt-5.5-codex, just GPT-5.5 plus the Codex harness. That's the model labs telling you, in their own way, that the harness is where the productization is happening. The model is becoming a substrate; the harness is becoming the product. Plan accordingly.
The Story Going Forward
Dirac will get its 17-point delta papered over within weeks. Cline will merge the techniques. Claude Code's next release will batch tool calls. JetBrains will ship hash-anchored edits in Junie. The harness work always gets absorbed back into the mainstream tools — that's the bitter lesson at work.
But the lesson before the lesson is this: for a window of months, sometimes years, the harness is where the gains live, and the people who pay attention to it ship measurably better software than the people who don't. The Dirac result is one more empirical brick in that wall. The Claude Code regression is another. The mattpocock skills explosion is another.
The model leaderboards aren't wrong — they're just incomplete. What you actually want, before picking your next agent stack, is the harness leaderboard nobody's published yet. Until it exists, you build it yourself: by reading the Show HN threads, watching which open-source agents top the model-specific charts, and noticing when the same harness shows up three times in the top 10 with three different models behind it.
That's the signal. The model varies. The harness wins.
Want more practitioner-level coverage of agent infrastructure? See our deep-dives on the Claude Code agentic dev stack, GPT-5.5 vs Claude Code in real use, and the Karpathy CLAUDE.md template that kicked off the skills-sharing wave.
ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
Join the discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related articles
Codex + Claude Code: The Paired-Agent Stack for 2026
When YC, HN, and GitHub converge on 'thin harness, fat skills' in 48 hours, the single-agent era ends. Here is how to wire Codex and Claude Code together.
Build Your Own Agentic OS: Phone, Pi, or MacBook in 2026
Three Claude Code stacks compared — phone via web UI, Raspberry Pi headless, MacBook power-user. Pick the one that fits your workflow.
Codex /goal Just Ate the Agent-Harness Category
OpenAI's Codex CLI shipped a /goal loop that absorbs the harness category overnight. Here's what survives — skills, memory, and tool integrations.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
WEEKLY. UNSUBSCRIBE ANYTIME.